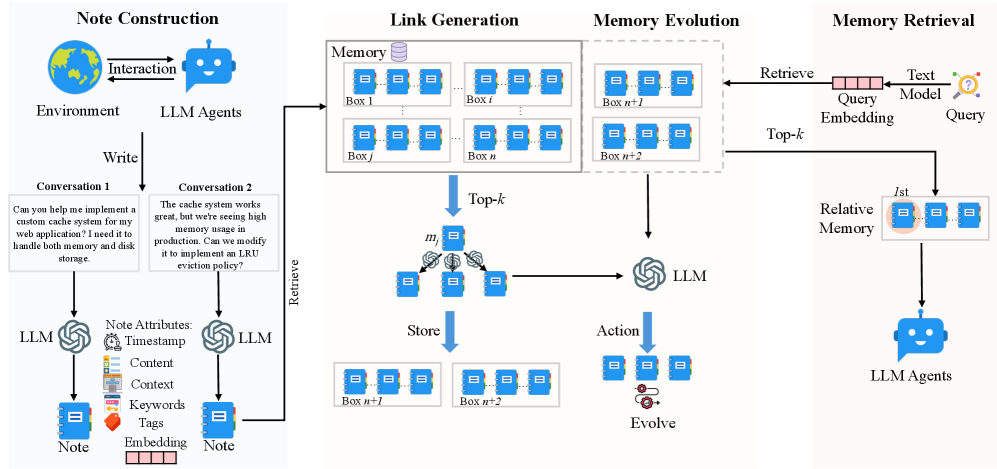
## Diagram: LLM Memory Management
### Overview
The image is a diagram illustrating the process of memory management using Large Language Models (LLMs). It is divided into four main sections: Note Construction, Link Generation, Memory Evolution, and Memory Retrieval. The diagram shows how user interactions are converted into notes, linked in memory, evolved over time, and retrieved when needed.
### Components/Axes
* **Titles:**
* Note Construction (Top-Left)
* Link Generation (Top-Center-Left)
* Memory Evolution (Top-Center-Right)
* Memory Retrieval (Top-Right)
* **Note Construction:**
* Environment: Depicted as a globe.
* LLM Agents: Depicted as a blue chatbot icon.
* Interaction: A bidirectional arrow between the Environment and LLM Agents.
* Write: A downward arrow indicating the writing process.
* Conversation 1: A text box containing the question, "Can you help me implement a custom cache system for my web application? I need it to handle both memory and disk storage."
* Conversation 2: A text box containing the statement, "The cache system works great, but we're seeing high memory usage in production. Can we modify it to implement an LRU eviction policy?"
* LLM: Represented by the LLM logo.
* Note Attributes:
* Timestamp: Clock icon.
* Content: List icon.
* Context: Document icon.
* Keywords: Tag icon.
* Tags: Orange tag icon.
* Embedding: A series of small rectangles.
* Note: Represented as a blue notebook icon.
* **Link Generation:**
* Memory: Represented as a database icon.
* Boxes: Labeled as Box 1, Box i, Box j, Box n. Each box contains three blue notebook icons.
* Top-k: A downward arrow indicating the top-k selection process.
* m: A node with three blue notebook icons, connected to other nodes via lines and small circular icons.
* Store: A downward arrow indicating the storing process.
* Boxes: Labeled as Box n+1, Box n+2. Each box contains three blue notebook icons.
* **Memory Evolution:**
* Boxes: Labeled as Box n+1, Box n+2. Each box contains three blue notebook icons.
* LLM: Represented by the LLM logo.
* Action: A downward arrow indicating the action process.
* Evolve: A node with three blue notebook icons and a gear icon.
* **Memory Retrieval:**
* Retrieve: An arrow pointing from the "Memory Evolution" section to a "Query Embedding" box.
* Query Embedding: A horizontal box labeled "Query Embedding" with "Text Model" above it.
* Query: A question mark icon.
* Top-k: An arrow pointing from the "Query Embedding" box to the "Relative Memory" box.
* Relative Memory: A box containing three blue notebook icons, with the leftmost icon highlighted with a pink circle and labeled "1st".
* LLM Agents: Depicted as a blue chatbot icon.
### Detailed Analysis or Content Details
* **Note Construction:** The process starts with an interaction between the environment and LLM agents. The agents write conversations, which are then processed by LLMs to create notes. These notes have attributes such as timestamp, content, context, keywords, tags, and embeddings.
* **Link Generation:** The notes are stored in memory boxes (Box 1 to Box n). A top-k selection process retrieves relevant notes, which are then stored in new memory boxes (Box n+1 and Box n+2).
* **Memory Evolution:** The notes in memory boxes (Box n+1 and Box n+2) are processed by an LLM, which takes action and evolves the notes.
* **Memory Retrieval:** A query is embedded using a text model. A top-k selection process retrieves relative memory, and the first (1st) item is highlighted. The retrieved information is then used by LLM agents.
### Key Observations
* The diagram illustrates a cyclical process of note creation, storage, evolution, and retrieval.
* LLMs play a central role in processing and evolving the notes.
* The top-k selection process is used in both link generation and memory retrieval.
* The diagram highlights the importance of note attributes in the memory management process.
### Interpretation
The diagram presents a high-level overview of how LLMs can be used for memory management. The process involves converting user interactions into structured notes, linking these notes in memory, evolving them over time, and retrieving them when needed. The use of top-k selection suggests a mechanism for prioritizing relevant information. The diagram emphasizes the importance of context and attributes in managing and retrieving information effectively. The cyclical nature of the process indicates a continuous learning and adaptation mechanism.