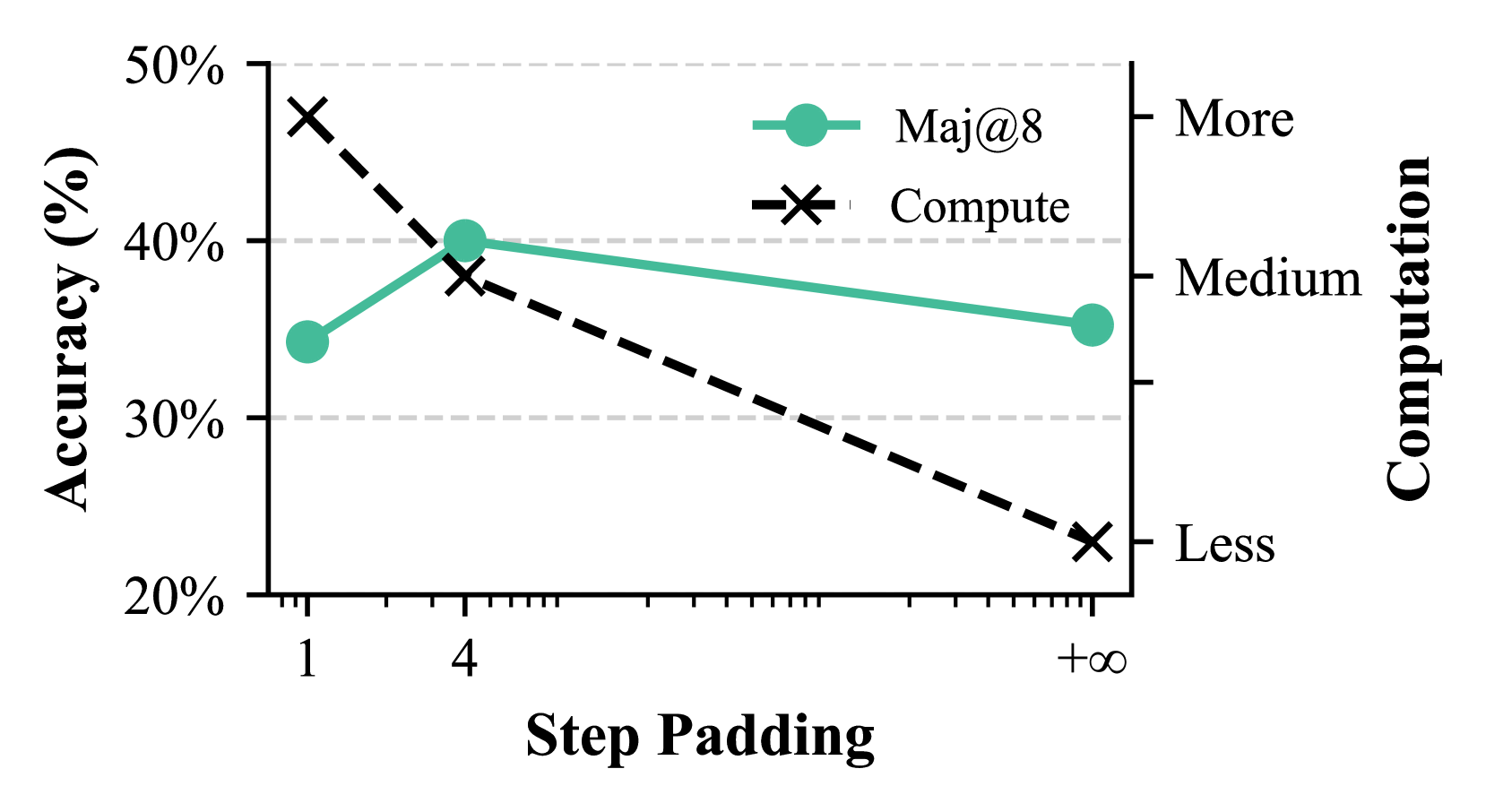
## Line Graph: Accuracy vs. Computation Trade-off
### Overview
The graph compares two metrics—**Accuracy (%)** and **Computation**—across varying levels of **Step Padding** (1, 4, +∞). Two data series are plotted:
- **Maj@8** (teal circles)
- **Compute** (black crosses)
### Components/Axes
- **X-axis (Step Padding)**: Discrete values at 1, 4, and +∞.
- **Left Y-axis (Accuracy %)**: Ranges from 20% to 50%, with gridlines at 20%, 30%, 40%, and 50%.
- **Right Y-axis (Computation)**: Categorical scale labeled **Less**, **Medium**, **More** (bottom to top).
- **Legend**: Located in the upper-right corner, mapping **Maj@8** (teal) and **Compute** (black).
### Detailed Analysis
1. **Maj@8 (teal circles)**:
- At Step Padding = 1: Accuracy ≈ 35%.
- At Step Padding = 4: Accuracy peaks at ≈ 40%.
- At Step Padding = +∞: Accuracy drops to ≈ 35%.
- **Trend**: Slightly increases then declines, forming a shallow "M" shape.
2. **Compute (black crosses)**:
- At Step Padding = 1: Accuracy ≈ 45%.
- At Step Padding = 4: Accuracy ≈ 35% (intersects Maj@8).
- At Step Padding = +∞: Accuracy ≈ 25%.
- **Trend**: Steadily declines, forming a downward slope.
### Key Observations
- **Intersection at Step Padding = 4**: Both metrics converge at ≈ 35% accuracy.
- **Computation vs. Accuracy**:
- **Compute** starts with higher accuracy (45% at Step Padding = 1) but requires **More** computation.
- **Maj@8** maintains moderate accuracy (35–40%) with **Medium** computation.
- **Divergence at +∞**: Compute’s accuracy plummets to 25%, while Maj@8 stabilizes at 35%.
### Interpretation
The graph illustrates a **trade-off between accuracy and computational cost**:
- **Compute** prioritizes initial accuracy but becomes inefficient at higher Step Padding, requiring disproportionate resources for diminishing returns.
- **Maj@8** balances accuracy and efficiency, maintaining stable performance with lower computational overhead.
- The **+∞** Step Padding scenario highlights scalability issues for Compute, suggesting it may not be viable for large-scale applications.
**Critical Insight**: Maj@8 offers a pragmatic middle ground, avoiding the extremes of high computational cost (Compute) or suboptimal accuracy at scale. This aligns with Pareto optimization principles in machine learning model selection.