TECHNICAL ASSET FINGERPRINT
0cb16acb2d49f5923d1102d9
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
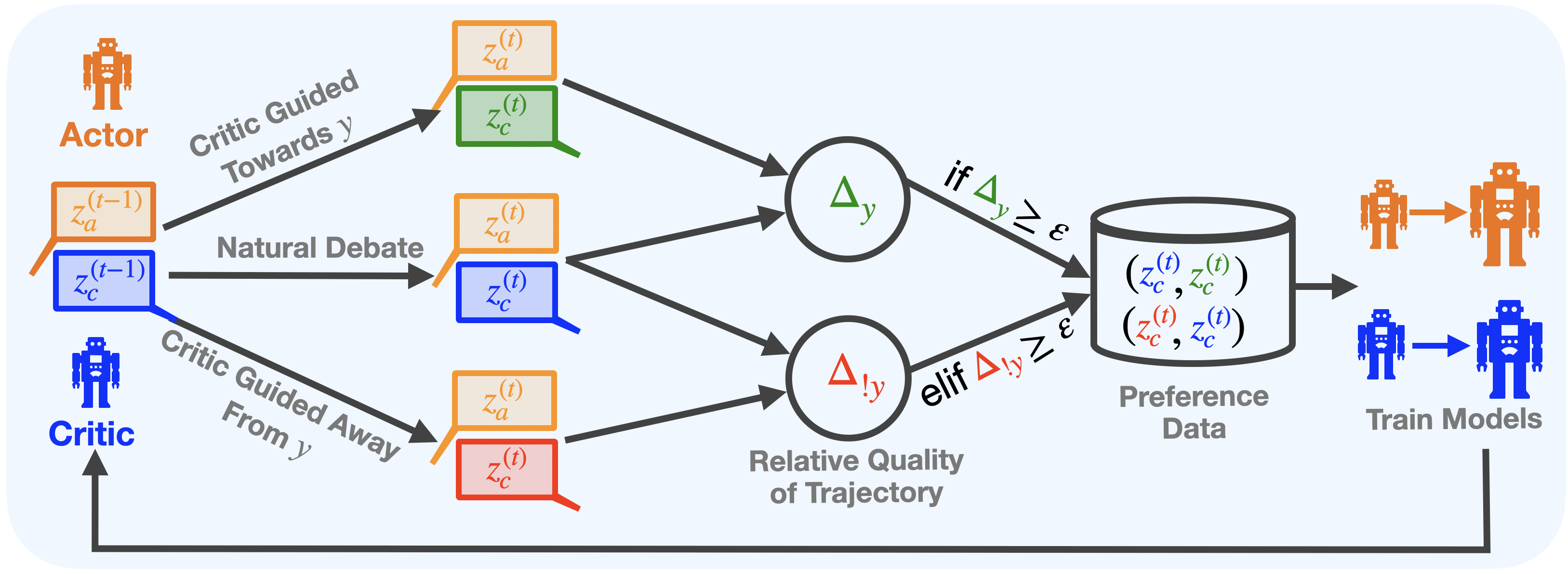
## Process Diagram: Actor-Critic Trajectory Generation for Preference Data
### Overview
This diagram illustrates a machine learning process where an "Actor" model and a "Critic" model interact over time steps to generate pairs of trajectories. These trajectories are compared to assess their relative quality concerning a target `y`. If the quality difference meets a threshold `ε`, the trajectory pairs are stored as preference data, which is subsequently used to train both the Actor and Critic models in a feedback loop.
### Components/Axes
The diagram is a flowchart with the following key components, flowing primarily from left to right:
1. **Actors & Critics (Left Side):**
* **Actor:** Represented by an orange robot icon. Its state at time `t-1` is denoted as `z_a^{(t-1)}` in an orange box.
* **Critic:** Represented by a blue robot icon. Its state at time `t-1` is denoted as `z_c^{(t-1)}` in a blue box.
2. **Trajectory Generation Paths (Center-Left):** Three distinct paths originate from the initial states:
* **Top Path (Critic Guided Towards y):** An arrow labeled "Critic Guided Towards y" leads to a pair of boxes: an orange `z_a^{(t)}` and a green `z_c^{(t)}`.
* **Middle Path (Natural Debate):** An arrow labeled "Natural Debate" leads to a pair of boxes: an orange `z_a^{(t)}` and a blue `z_c^{(t)}`.
* **Bottom Path (Critic Guided Away From y):** An arrow labeled "Critic Guided Away From y" leads to a pair of boxes: an orange `z_a^{(t)}` and a red `z_c^{(t)}`.
3. **Quality Comparison (Center):**
* Two circular nodes labeled "Relative Quality of Trajectory".
* The top circle contains `Δ_y` (green delta symbol). It receives inputs from the top and middle trajectory pairs.
* The bottom circle contains `Δ_{!y}` (red delta symbol with an exclamation mark). It receives inputs from the middle and bottom trajectory pairs.
4. **Decision Logic & Data Storage (Center-Right):**
* **Condition 1:** An arrow from `Δ_y` is labeled "if `Δ_y ≥ ε`".
* **Condition 2:** An arrow from `Δ_{!y}` is labeled "elif `Δ_{!y} ≥ ε`".
* Both arrows point to a cylinder icon representing a database.
* **Database Contents:** The database is labeled "Preference Data" and contains two pairs of trajectories:
* `(z_c^{(t)}, z_c^{(t)})` (The first `z_c` is blue, the second is green).
* `(z_c^{(t)}, z_c^{(t)})` (The first `z_c` is red, the second is blue).
5. **Model Training & Feedback Loop (Right Side):**
* An arrow leads from the database to a section labeled "Train Models".
* This section shows an orange Actor robot evolving into a larger orange Actor robot, and a blue Critic robot evolving into a larger blue Critic robot.
* A long feedback arrow runs from the "Train Models" output back to the initial Critic icon on the far left, closing the loop.
### Detailed Analysis
* **Process Flow:** The system starts with the previous states of the Actor (`z_a^{(t-1)}`) and Critic (`z_c^{(t-1)}`). Three different interaction modes generate new state pairs at time `t`:
1. The Critic actively guides the Actor *toward* a target `y`, producing a green Critic state.
2. The Actor and Critic engage in a "Natural Debate," producing a standard blue Critic state.
3. The Critic actively guides the Actor *away from* the target `y`, producing a red Critic state.
* **Comparison Logic:** The system then compares the quality of these generated Critic trajectories:
* `Δ_y` measures the quality difference between the "Guided Towards y" (green) trajectory and the "Natural Debate" (blue) trajectory.
* `Δ_{!y}` measures the quality difference between the "Guided Away From y" (red) trajectory and the "Natural Debate" (blue) trajectory.
* **Data Collection Rule:** A trajectory pair is stored as preference data only if the measured quality difference (`Δ_y` or `Δ_{!y}`) is greater than or equal to a predefined threshold `ε`. This ensures only significant comparisons are saved.
* **Stored Data:** The database stores ordered pairs of Critic trajectories. The notation `(z_c^{(t)}, z_c^{(t)})` with different colors implies a preference order: the first element is preferred over the second. For example, `(blue, green)` likely means the blue (debate) trajectory is preferred over the green (guided towards y) one, and `(red, blue)` means the red (guided away) is preferred over the blue.
* **Training:** The collected preference data is used to train both the Actor and Critic models, improving their performance. The trained Critic is then fed back into the next iteration of the process.
### Key Observations
1. **Color-Coded Semantics:** Colors are used consistently to denote meaning: Orange (Actor), Blue (Critic baseline/debate), Green (Critic guided towards target `y`), Red (Critic guided away from target `y`).
2. **Asymmetric Guidance:** The process explicitly generates data by having the Critic provide both positive (towards `y`) and negative (away from `y`) guidance, creating a contrast for learning.
3. **Threshold-Based Filtering:** The use of `ε` acts as a quality filter, preventing the storage of trivial or noisy comparisons where the quality difference is negligible.
4. **Closed-Loop System:** The diagram depicts a complete, iterative learning cycle where generated data improves the models, which in turn generate better data.
### Interpretation
This diagram outlines a sophisticated **self-improving AI training framework**, likely for reinforcement learning or alignment tasks. The core idea is to use a Critic model not just to evaluate, but to actively *create* contrasting examples (trajectories) by guiding an Actor model. By comparing the quality of these deliberately contrasted examples (guided vs. natural) and storing only the decisive comparisons, the system efficiently builds a high-quality preference dataset.
The process addresses a key challenge in AI training: generating meaningful feedback data. Instead of relying solely on human feedback, the Critic automates the creation of training signals. The "Natural Debate" path serves as a crucial baseline. The final training step closes the loop, suggesting the goal is to iteratively refine both models so the Critic becomes better at identifying quality and the Actor becomes better at achieving desired outcomes (`y`). The entire system is designed for autonomous, scalable improvement.
DECODING INTELLIGENCE...