## Flowchart: Actor-Critic System with Natural Debate and Preference-Based Training
### Overview
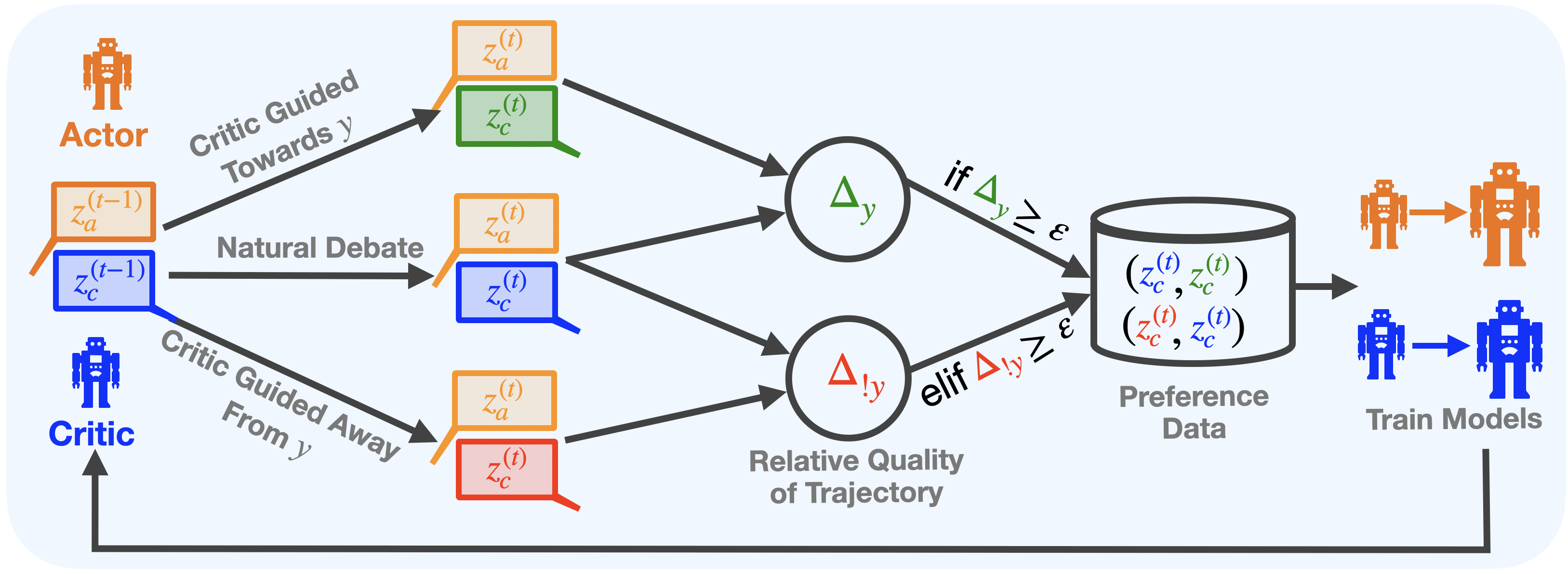
The diagram illustrates a cyclical process involving an **Actor** and a **Critic** in a reinforcement learning framework. The system incorporates a "Natural Debate" mechanism between the Actor and Critic, guided by trajectory quality comparisons. Key components include action generation, critique evaluation, relative quality assessment, and preference data collection for model training.
---
### Components/Axes
1. **Actors/Critics**:
- **Actor** (orange robot icon): Generates actions (`z_a(t-1)`).
- **Critic** (blue robot icon): Evaluates actions (`z_c(t-1)`).
2. **Process Flow**:
- **Natural Debate**: Interaction between Actor and Critic outputs (`z_a(t-1)`, `z_c(t-1)`).
- **Critic Guided Towards y**: Optimizes actions toward a target (`y`).
- **Critic Guided Away From y**: Penalizes deviations from `y`.
- **Relative Quality of Trajectory**: Compares trajectories (`Δy`, `Δ!y`).
- **Preference Data**: Collected when quality differences exceed threshold `ε`.
- **Train Models**: Updates models using preference data.
---
### Detailed Analysis
1. **Action Generation**:
- Actor produces action `z_a(t-1)`.
- Critic evaluates action with `z_c(t-1)`.
2. **Debate and Guidance**:
- **Critic Guided Towards y**: Uses `z_a(t)` and `z_c(t)` to refine actions toward `y`.
- **Critic Guided Away From y**: Uses `z_a(t)` and `z_c(t)` to penalize suboptimal actions.
3. **Quality Assessment**:
- **Δy**: Measures improvement toward `y`.
- **Δ!y**: Measures deviation from `y`.
- If `Δy ≥ ε` or `Δ!y ≥ ε`, preference data (`(z_c(t), z_c(t))`) is stored.
4. **Model Training**:
- Preference data trains models to prioritize high-quality trajectories.
---
### Key Observations
- **Cyclical Feedback**: The Critic’s output (`z_c(t)`) directly influences the Actor’s next action (`z_a(t)`), creating a closed-loop system.
- **Threshold ε**: Acts as a decision boundary for collecting preference data, ensuring only significant quality differences are retained.
- **Dual Guidance**: The Critic simultaneously guides the Actor toward `y` and away from poor trajectories, balancing exploration and exploitation.
---
### Interpretation
This diagram represents an **Actor-Critic Reinforcement Learning (ACRL) system** enhanced with a "Natural Debate" mechanism. The Critic’s dual role—guiding actions toward a target (`y`) while penalizing deviations—suggests a focus on **trajectory optimization**. The use of `Δy` and `Δ!y` implies a comparison between the Actor’s current trajectory and an ideal or baseline trajectory (`y`).
The threshold `ε` ensures that only meaningful improvements or deviations are used for training, preventing noise from minor fluctuations. The final step—training models on preference data—indicates a **human-in-the-loop** or **comparative learning** approach, where relative quality judgments (e.g., human preferences) refine the Actor’s policy. This could align with methods like **Reinforcement Learning from Human Feedback (RLHF)** or **Comparative RL**.
The diagram emphasizes **iterative improvement**, where the Critic’s feedback continuously shapes the Actor’s behavior, balancing exploration (via "Critic Guided Away From y") and exploitation (via "Critic Guided Towards y"). The absence of explicit numerical values suggests a conceptual framework rather than a specific implementation.