# Technical Document Extraction: IMDb Sentiment Generation Analysis
## 1. Document Overview
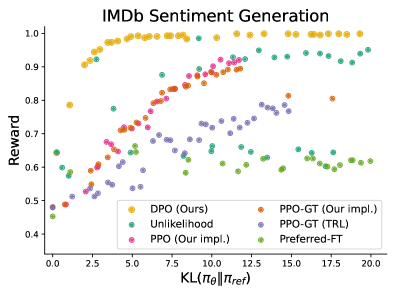
This image is a scatter plot representing the performance of various Reinforcement Learning from Human Feedback (RLHF) and fine-tuning algorithms on an IMDb sentiment generation task. It evaluates the trade-off between the achieved reward and the divergence from a reference model.
## 2. Component Isolation
### Header
* **Title:** IMDb Sentiment Generation
### Main Chart Area
* **Y-Axis Label:** Reward
* **Y-Axis Scale:** 0.4 to 1.0 (increments of 0.1)
* **X-Axis Label:** $KL(\pi_\theta || \pi_{ref})$
* **X-Axis Scale:** 0.0 to 20.0 (increments of 2.5)
### Legend (Spatial Grounding: Bottom Center)
The legend contains six categories:
1. **DPO (Ours):** Yellow/Gold circles
2. **Unlikelihood:** Teal/Green-blue circles
3. **PPO (Our impl.):** Pink/Magenta circles
4. **PPO-GT (Our impl.):** Orange/Brown circles
5. **PPO-GT (TRL):** Purple/Lavender circles
6. **Preferred-FT:** Light Green circles
---
## 3. Data Series Analysis and Trends
| Algorithm | Trend Description | Key Data Points |
| :--- | :--- | :--- |
| **DPO (Ours)** | Rapid logarithmic growth. Reaches maximum reward (~1.0) quickly at low KL values and maintains a stable ceiling. | Starts at ~0.9 reward at $KL \approx 2.5$. Hits ~1.0 reward at $KL \approx 5.0$ and stays through $KL=20.0$. |
| **PPO (Our impl.)** | Strong linear upward trend. Consistent improvement in reward as KL increases; does not reach 1.0 ceiling in range. | Starts at ~0.53 reward ($KL \approx 2.0$). Reaches ~0.92 reward at $KL \approx 11.0$. |
| **PPO-GT (Our impl.)** | Steady upward trend, following PPO (Our impl.) trajectory but slightly lower reward for same KL values. | Starts at ~0.49 reward ($KL \approx 1.0$). Reaches ~0.89 reward at $KL \approx 12.0$. |
| **Unlikelihood** | High variance with general upward slope. Achieves high rewards but requires higher KL divergence than DPO. | Scattered between 0.6 and 0.95 reward. Reaches ~0.95 reward at $KL \approx 13.0$ and $KL \approx 20.0$. |
| **PPO-GT (TRL)** | Moderate upward trend with significant noise. Performs consistently lower than "Our impl." versions of PPO. | Starts at ~0.48 reward ($KL \approx 0.0$). Reaches a peak of ~0.79 reward at $KL \approx 13.0$. |
| **Preferred-FT** | Relatively flat or slightly parabolic. Least improvement in reward as KL increases, plateauing or dipping. | Starts at ~0.45 reward ($KL \approx 0.0$). Peaks around ~0.65 reward ($KL \approx 5.0$). |
---
## 4. Summary of Findings
The chart demonstrates that **DPO (Ours)** is the most efficient algorithm shown, achieving the highest possible reward with the lowest deviation from the reference model (lowest KL divergence). The PPO implementations show a clear trade-off where higher rewards are possible at the cost of higher KL divergence. **Preferred-FT** is the least effective method in this specific benchmark, failing to reach high reward levels regardless of the KL divergence.