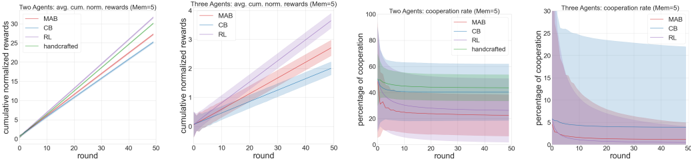
\n
## Line Charts: Multi-Agent Reinforcement Learning Performance
### Overview
The image displays four horizontally arranged line charts comparing the performance of different agent strategies in a multi-agent reinforcement learning context. The charts are divided into two pairs: the left pair shows "cumulative normalized rewards" for two-agent and three-agent scenarios, while the right pair shows "percentage of cooperation" for the same scenarios. All charts share a common x-axis ("round") and use a memory parameter of 5 (Mem=5).
### Components/Axes
* **Chart 1 (Far Left):**
* **Title:** "Two Agents: cum. norm. rewards (Mem=5)"
* **Y-axis:** "cumulative normalized rewards" (Scale: 0 to 4)
* **X-axis:** "round" (Scale: 0 to 50)
* **Legend (Top-Left):** MAB (red line), CB (blue line), RL (green line), handcrafted (purple line).
* **Chart 2 (Center-Left):**
* **Title:** "Three Agents: cum. norm. rewards (Mem=5)"
* **Y-axis:** "cumulative normalized rewards" (Scale: 0 to 4)
* **X-axis:** "round" (Scale: 0 to 50)
* **Legend (Top-Left):** MAB (red line), CB (blue line), RL (green line), handcrafted (purple line).
* **Chart 3 (Center-Right):**
* **Title:** "Two Agents: cooperation rate (Mem=5)"
* **Y-axis:** "percentage of cooperation" (Scale: 0 to 100)
* **X-axis:** "round" (Scale: 0 to 50)
* **Legend (Top-Right):** MAB (red line), CB (blue line), RL (green line), handcrafted (purple line).
* **Chart 4 (Far Right):**
* **Title:** "Three Agents: cooperation rate (Mem=5)"
* **Y-axis:** "percentage of cooperation" (Scale: 0 to 30)
* **X-axis:** "round" (Scale: 0 to 50)
* **Legend (Top-Right):** MAB (red line), CB (blue line), RL (green line), handcrafted (purple line).
### Detailed Analysis
**Chart 1: Two Agents - Cumulative Rewards**
* **Trend:** All four lines show a steady, near-linear upward trend from round 0 to 50.
* **Data Points (Approximate at Round 50):**
* MAB (Red): ~3.8
* CB (Blue): ~3.6
* RL (Green): ~3.2
* handcrafted (Purple): ~3.0
* **Confidence Intervals (Shaded Areas):** All series have relatively narrow confidence bands that widen slightly over time. The bands for MAB and CB are the narrowest.
**Chart 2: Three Agents - Cumulative Rewards**
* **Trend:** All lines show an upward trend, but with more pronounced curvature (slight deceleration) compared to the two-agent case.
* **Data Points (Approximate at Round 50):**
* MAB (Red): ~3.5
* CB (Blue): ~3.3
* RL (Green): ~2.8
* handcrafted (Purple): ~2.5
* **Confidence Intervals:** Confidence bands are significantly wider than in the two-agent scenario, indicating higher variance in performance. The handcrafted agent's band is the widest.
**Chart 3: Two Agents - Cooperation Rate**
* **Trend:** The cooperation rates for all agents show an initial rapid change followed by stabilization.
* MAB (Red): Starts near 0%, rises sharply to ~40% by round 10, then stabilizes between 35-40%.
* CB (Blue): Starts near 100%, drops sharply to ~60% by round 10, then stabilizes between 55-65%.
* RL (Green): Starts near 50%, remains relatively stable around 45-50% throughout.
* handcrafted (Purple): Starts near 0%, rises to ~20% by round 10, then stabilizes between 15-25%.
* **Confidence Intervals:** Very wide, overlapping bands for all series, suggesting high variability and less distinct separation between agent behaviors.
**Chart 4: Three Agents - Cooperation Rate**
* **Trend:** All agents show a general downward trend in cooperation over time.
* MAB (Red): Starts near 0%, rises slightly to ~5% by round 10, then slowly declines to near 0%.
* CB (Blue): Starts near 30%, declines steadily to ~5% by round 50.
* RL (Green): Starts near 15%, declines slowly to ~5% by round 50.
* handcrafted (Purple): Starts near 0%, rises to ~5% by round 10, then declines back to near 0%.
* **Confidence Intervals:** Extremely wide bands, especially for CB and RL, often spanning 20-30 percentage points. This indicates very high uncertainty in the cooperation rate measurements for the three-agent scenario.
### Key Observations
1. **Performance Hierarchy:** In both two-agent and three-agent cumulative reward charts, the performance order is consistent: MAB > CB > RL > handcrafted.
2. **Scalability Impact:** Moving from two to three agents reduces the cumulative reward for all strategies and dramatically increases the variance (wider confidence intervals).
3. **Cooperation Dynamics:** Cooperation rates are highly scenario-dependent. Two-agent scenarios show stable, differentiated cooperation levels, while three-agent scenarios show a universal collapse in cooperation over time.
4. **Uncertainty:** The confidence intervals for cooperation rates are much wider than for cumulative rewards, suggesting cooperation is a more volatile or difficult-to-measure metric in this experiment.
### Interpretation
The data suggests that the **MAB (Multi-Armed Bandit)** and **CB (likely Counterfactual or Cooperative Baseline)** strategies are more effective at maximizing cumulative rewards than standard **RL (Reinforcement Learning)** or a **handcrafted** policy, in both two-agent and three-agent settings. Their superiority is more pronounced in the simpler two-agent environment.
The cooperation rate charts reveal a critical insight: **higher reward does not necessarily correlate with higher cooperation.** In the two-agent case, the high-performing CB agent maintains the highest cooperation rate (~60%), but the top-performing MAB agent has a lower rate (~40%). In the three-agent case, cooperation decays for all agents, suggesting the environment becomes more competitive or less conducive to cooperative equilibria as the number of agents increases. The extreme variance in the three-agent cooperation data indicates that outcomes are highly sensitive to initial conditions or stochastic elements in the simulation.
Overall, the charts demonstrate that agent strategy significantly impacts both performance and social behavior (cooperation), and that these dynamics become more complex and less predictable as the system scales from two to three agents. The handcrafted policy consistently underperforms, indicating that learned or optimized strategies (MAB, CB) are preferable.