## Line Graphs: Cumulative Normalized Rewards and Cooperation Rates Across Agent Configurations
### Overview
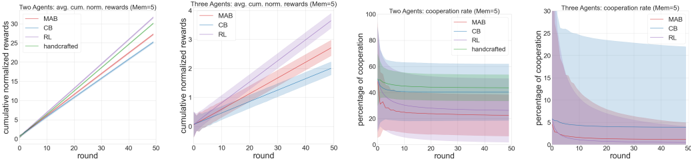
The image contains four line graphs comparing the performance of four methods (MAB, CB, RL, handcrafted) across two agent configurations (two agents and three agents). The graphs track cumulative normalized rewards and cooperation rates over 50 rounds. Shaded regions represent confidence intervals (likely ±1 standard deviation).
---
### Components/Axes
1. **Graph 1 (Two Agents: Cumulative Rewards)**
- **X-axis**: Rounds (0–50)
- **Y-axis**: Cumulative normalized rewards (0–30)
- **Legend**:
- MAB (red)
- CB (blue)
- RL (purple)
- Handcrafted (green)
- **Shading**: Confidence intervals around lines
2. **Graph 2 (Three Agents: Cumulative Rewards)**
- **X-axis**: Rounds (0–50)
- **Y-axis**: Cumulative normalized rewards (0–4)
- **Legend**:
- MAB (red)
- CB (blue)
- RL (purple)
- **Shading**: Confidence intervals
3. **Graph 3 (Two Agents: Cooperation Rate)**
- **X-axis**: Rounds (0–50)
- **Y-axis**: Percentage of cooperation (0–100%)
- **Legend**:
- MAB (red)
- CB (blue)
- RL (purple)
- Handcrafted (green)
- **Shading**: Confidence intervals
4. **Graph 4 (Three Agents: Cooperation Rate)**
- **X-axis**: Rounds (0–50)
- **Y-axis**: Percentage of cooperation (0–30%)
- **Legend**:
- MAB (red)
- CB (blue)
- RL (purple)
- **Shading**: Confidence intervals
---
### Detailed Analysis
#### Graph 1 (Two Agents: Rewards)
- **Trends**:
- All methods show upward slopes.
- RL (purple) and handcrafted (green) outperform MAB (red) and CB (blue) consistently.
- By round 50, RL reaches ~30 rewards, handcrafted ~28, MAB ~26, CB ~24.
- **Key Data Points**:
- At round 10: RL (~10), handcrafted (~9), MAB (~8), CB (~7).
- At round 30: RL (~22), handcrafted (~21), MAB (~19), CB (~17).
#### Graph 2 (Three Agents: Rewards)
- **Trends**:
- All methods increase, but rewards plateau earlier.
- RL (purple) leads, followed by MAB (red), CB (blue).
- By round 50: RL (~3.5), MAB (~3), CB (~2.5).
- **Key Data Points**:
- At round 10: RL (~1.2), MAB (~1), CB (~0.8).
- At round 30: RL (~2.8), MAB (~2.5), CB (~2.2).
#### Graph 3 (Two Agents: Cooperation Rate)
- **Trends**:
- MAB (red) drops sharply to ~20% by round 10, then stabilizes.
- RL (purple) and handcrafted (green) maintain ~60–80% cooperation.
- CB (blue) declines gradually to ~40%.
- **Key Data Points**:
- At round 5: MAB (~80%), RL (~70%), handcrafted (~65%), CB (~60%).
- At round 30: MAB (~22%), RL (~65%), handcrafted (~60%), CB (~40%).
#### Graph 4 (Three Agents: Cooperation Rate)
- **Trends**:
- MAB (red) drops steeply to ~5% by round 10, then stabilizes.
- CB (blue) declines to ~10%, RL (purple) to ~15%.
- Handcrafted (green) in Graph 3 (~40%) is absent here, suggesting lower performance with three agents.
- **Key Data Points**:
- At round 5: MAB (~25%), CB (~20%), RL (~18%).
- At round 30: MAB (~5%), CB (~8%), RL (~12%).
---
### Key Observations
1. **Reward Performance**:
- RL and handcrafted methods achieve higher cumulative rewards in both agent configurations.
- Three-agent rewards are significantly lower than two-agent rewards across all methods.
2. **Cooperation Rates**:
- MAB performs poorly in cooperation, especially with three agents.
- Handcrafted methods show higher cooperation in two-agent settings but are omitted in three-agent graphs, implying inferior scalability.
- RL maintains moderate cooperation rates but declines with increased agents.
3. **Confidence Intervals**:
- Shaded regions indicate variability; RL and handcrafted show narrower intervals (more consistent performance).
- MAB’s wide intervals in cooperation graphs suggest instability.
---
### Interpretation
- **Method Efficacy**:
- RL and handcrafted methods excel in reward maximization but face challenges in maintaining cooperation as agent numbers increase.
- MAB struggles with cooperation, particularly in multi-agent scenarios, despite decent reward performance.
- **Scalability Issues**:
- Three-agent configurations reduce both rewards and cooperation rates, highlighting difficulties in coordination.
- Handcrafted methods may lack adaptability in complex environments (e.g., three agents).
- **Trade-offs**:
- Methods optimized for rewards (RL, handcrafted) may sacrifice cooperation, and vice versa.
- The absence of handcrafted in three-agent cooperation graphs suggests it underperforms or was excluded due to poor results.
- **Confidence Intervals**:
- Narrower intervals for RL/handcrafted imply more reliable performance, while MAB’s wide intervals indicate high variance in outcomes.
This analysis underscores the need for methods that balance reward optimization and cooperation, especially in scalable multi-agent systems.