\n
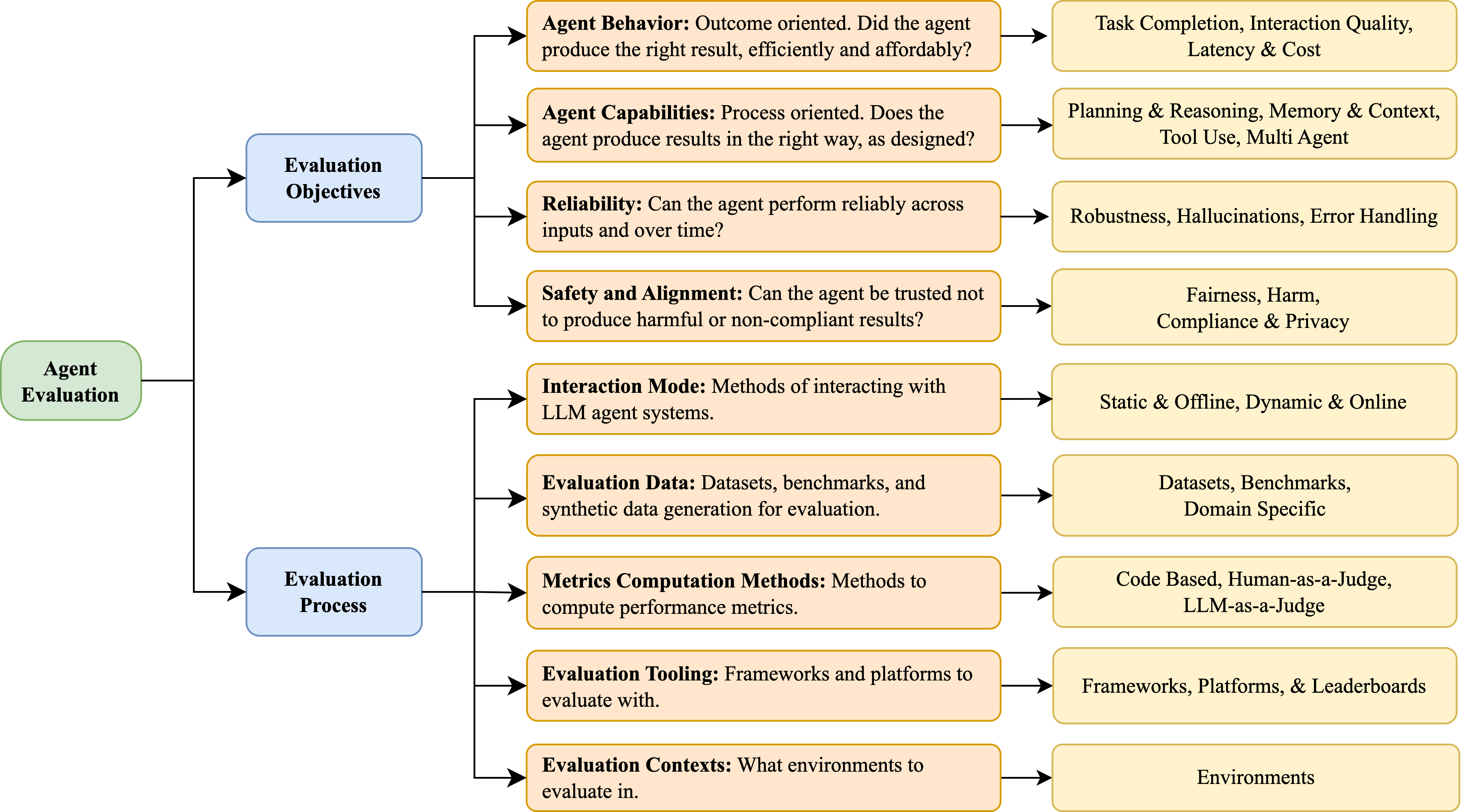
## Diagram: Agent Evaluation Framework
### Overview
This diagram illustrates a framework for evaluating Large Language Model (LLM) agents. It organizes evaluation aspects into four main categories: Evaluation Objectives, Agent Evaluation, Evaluation Process, and their corresponding considerations. The diagram uses a flow-chart style with boxes representing categories and arrows indicating relationships between them.
### Components/Axes
The diagram consists of four main rectangular blocks labeled:
1. **Evaluation Objectives** (Top-Left)
2. **Agent Evaluation** (Left-Center)
3. **Evaluation Process** (Bottom-Left)
4. Each of these blocks is connected via arrows to a corresponding block on the right side detailing specific considerations.
The right-side blocks are labeled with specific evaluation aspects:
* Task Completion, Interaction Quality, Latency & Cost
* Planning & Reasoning, Memory & Context, Tool Use, Multi Agent
* Robustness, Hallucinations, Error Handling
* Fairness, Harm, Compliance & Privacy
* Static & Offline, Dynamic & Online
* Datasets, Benchmarks, Domain Specific
* Code Based, Human-as-a-Judge, LLM-as-a-Judge
* Frameworks, Platforms, & Leaderboards
* Environments
### Detailed Analysis or Content Details
The diagram details the following aspects of agent evaluation:
**Evaluation Objectives:**
* **Agent Behavior:** Outcome oriented. Did the agent produce the right result, efficiently and affordably? – Connected to: Task Completion, Interaction Quality, Latency & Cost.
* **Agent Capabilities:** Process oriented. Does the agent produce results in the right way, as designed? – Connected to: Planning & Reasoning, Memory & Context, Tool Use, Multi Agent.
* **Reliability:** Can the agent perform reliably across inputs and over time? – Connected to: Robustness, Hallucinations, Error Handling.
* **Safety and Alignment:** Can the agent be trusted not to produce harmful or non-compliant results? – Connected to: Fairness, Harm, Compliance & Privacy.
**Agent Evaluation:**
* **Interaction Mode:** Methods of interacting with LLM agent systems. – Connected to: Static & Offline, Dynamic & Online.
* **Evaluation Data:** Datasets, benchmarks, and synthetic data generation for evaluation. – Connected to: Datasets, Benchmarks, Domain Specific.
* **Metrics Computation Methods:** Methods to compute performance metrics. – Connected to: Code Based, Human-as-a-Judge, LLM-as-a-Judge.
* **Evaluation Tooling:** Frameworks and platforms to evaluate with. – Connected to: Frameworks, Platforms, & Leaderboards.
* **Evaluation Contexts:** What environments to evaluate in. – Connected to: Environments.
The arrows indicate a directional relationship, suggesting that the objectives and evaluation aspects influence the evaluation process.
### Key Observations
The diagram presents a comprehensive framework, covering both the *what* (objectives) and the *how* (process) of agent evaluation. It highlights the multi-faceted nature of evaluation, encompassing behavior, capabilities, reliability, and safety. The inclusion of different interaction modes, data sources, metrics, tooling, and contexts emphasizes the need for a holistic approach.
### Interpretation
This diagram suggests a structured approach to evaluating LLM agents, moving beyond simple performance metrics to consider broader aspects like safety, alignment, and reliability. The framework emphasizes the importance of defining clear evaluation objectives and selecting appropriate methods and tools to assess agent performance across various contexts. The connections between the left and right sides of the diagram indicate that the evaluation process is informed by the objectives and considerations outlined. The diagram is a high-level overview and doesn't delve into specific metrics or methodologies, but it provides a valuable roadmap for developing a robust agent evaluation strategy. It is a conceptual model, not a data-driven chart. The diagram is intended to be a guide for thinking about the different aspects of agent evaluation, rather than a precise set of instructions.