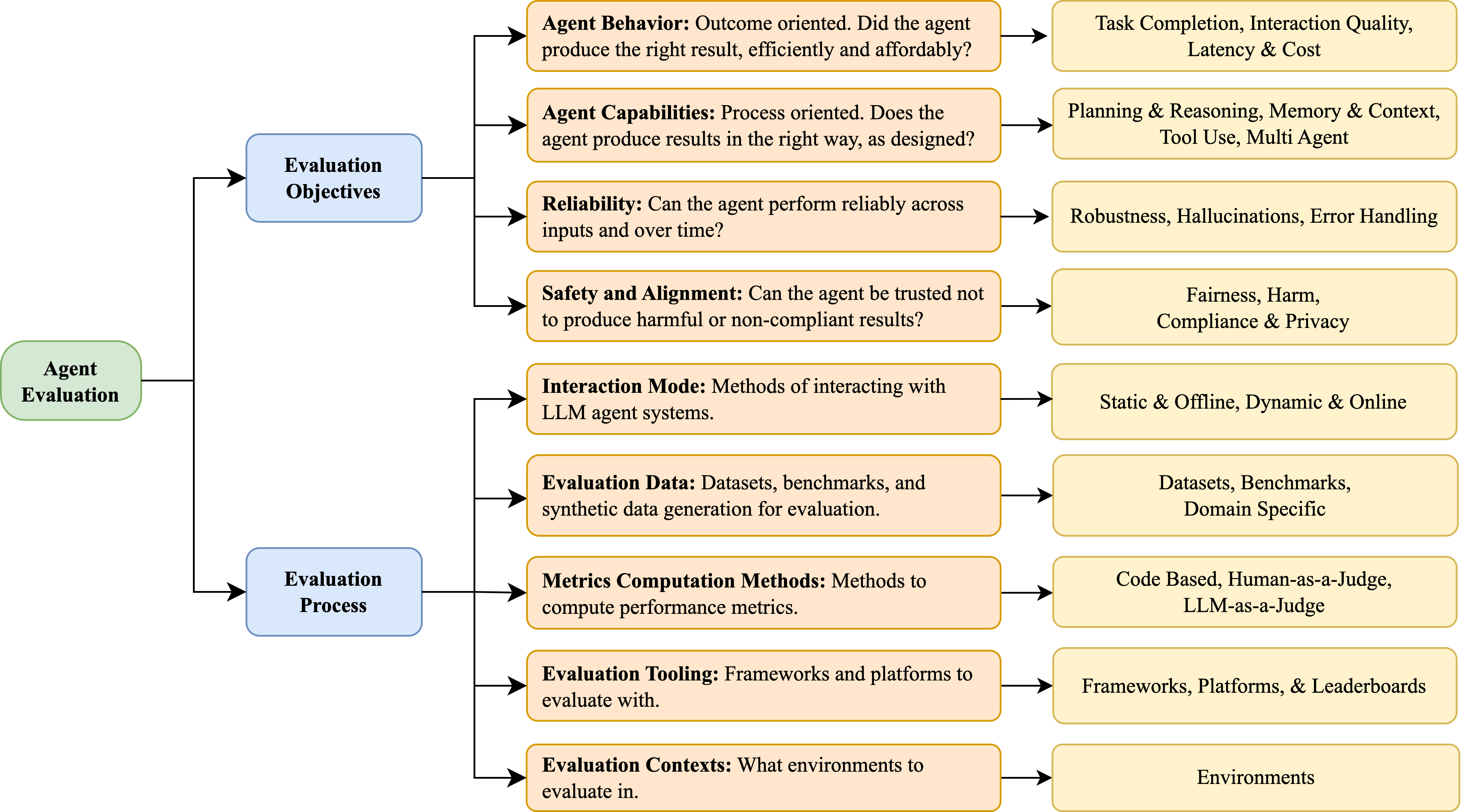
## Diagram: Agent Evaluation Framework
### Overview
The image displays a hierarchical flowchart outlining a comprehensive framework for evaluating AI agents. The diagram is structured as a tree, flowing from left to right, starting with a root concept that branches into two primary categories, which further subdivide into specific evaluation dimensions and their corresponding components or metrics.
### Components/Axes
The diagram is organized into four distinct layers, differentiated by color and position:
1. **Root Node (Green, Far Left):** "Agent Evaluation"
2. **Primary Categories (Blue, Center-Left):** Two main branches:
* "Evaluation Objectives"
* "Evaluation Process"
3. **Evaluation Dimensions (Orange, Center):** Specific areas of focus under each primary category.
4. **Components/Metrics (Yellow, Far Right):** Concrete elements, methods, or metrics associated with each evaluation dimension.
Arrows connect each node to its children, indicating a hierarchical and logical relationship. The flow is strictly left-to-right.
### Detailed Analysis
**Branch 1: Evaluation Objectives**
This branch defines *what* aspects of an agent should be evaluated.
* **Dimension 1: Agent Behavior**
* **Description:** "Outcome oriented. Did the agent produce the right result, efficiently and affordably?"
* **Components:** "Task Completion, Interaction Quality, Latency & Cost"
* **Dimension 2: Agent Capabilities**
* **Description:** "Process oriented. Does the agent produce results in the right way, as designed?"
* **Components:** "Planning & Reasoning, Memory & Context, Tool Use, Multi Agent"
* **Dimension 3: Reliability**
* **Description:** "Can the agent perform reliably across inputs and over time?"
* **Components:** "Robustness, Hallucinations, Error Handling"
* **Dimension 4: Safety and Alignment**
* **Description:** "Can the agent be trusted not to produce harmful or non-compliant results?"
* **Components:** "Fairness, Harm, Compliance & Privacy"
**Branch 2: Evaluation Process**
This branch defines *how* an agent evaluation is conducted.
* **Dimension 1: Interaction Mode**
* **Description:** "Methods of interacting with LLM agent systems."
* **Components:** "Static & Offline, Dynamic & Online"
* **Dimension 2: Evaluation Data**
* **Description:** "Datasets, benchmarks, and synthetic data generation for evaluation."
* **Components:** "Datasets, Benchmarks, Domain Specific"
* **Dimension 3: Metrics Computation Methods**
* **Description:** "Methods to compute performance metrics."
* **Components:** "Code Based, Human-as-a-Judge, LLM-as-a-Judge"
* **Dimension 4: Evaluation Tooling**
* **Description:** "Frameworks and platforms to evaluate with."
* **Components:** "Frameworks, Platforms, & Leaderboards"
* **Dimension 5: Evaluation Contexts**
* **Description:** "What environments to evaluate in."
* **Components:** "Environments"
### Key Observations
1. **Clear Dichotomy:** The framework cleanly separates the *goals* of evaluation (Objectives) from the *methodology* (Process).
2. **Comprehensive Scope:** The "Objectives" branch covers a holistic view of agent performance, from raw outcomes (Behavior) to internal processes (Capabilities), stability (Reliability), and ethical constraints (Safety).
3. **Process Granularity:** The "Process" branch breaks down the practical steps of evaluation into five distinct, actionable categories, moving from setup (Interaction Mode, Data) to execution (Metrics, Tooling) and environment (Contexts).
4. **Visual Hierarchy:** The color coding (Green -> Blue -> Orange -> Yellow) and spatial arrangement effectively communicate the increasing level of detail from left to right.
### Interpretation
This diagram presents a structured taxonomy for the emerging field of AI agent evaluation. It moves beyond simple accuracy metrics to advocate for a multi-faceted assessment.
* **Relationship Between Elements:** The "Evaluation Objectives" define the *requirements* for a good agent. The "Evaluation Process" provides the *operational blueprint* to measure those requirements. For example, to evaluate the "Reliability" objective, one would need to select an appropriate "Interaction Mode" (e.g., Dynamic & Online), use relevant "Evaluation Data" (e.g., Domain Specific benchmarks), and apply a "Metrics Computation Method" (e.g., Code Based for robustness checks).
* **Underlying Philosophy:** The framework implies that a trustworthy agent must be evaluated not just on *what* it does, but *how* it does it, *how consistently* it does it, and *within what ethical boundaries*. The inclusion of "LLM-as-a-Judge" and "Multi Agent" components acknowledges the specific challenges and paradigms of modern LLM-based systems.
* **Practical Utility:** This serves as a checklist or reference model for researchers and engineers designing evaluation suites. It ensures that critical dimensions like safety, tool use, and evaluation context are not overlooked in favor of simpler task-completion metrics. The separation of "Tooling" and "Contexts" highlights that the choice of platform and the environment (e.g., simulated vs. real-world) are first-class concerns in rigorous evaluation.