## Flowchart: Agent Evaluation Framework
### Overview
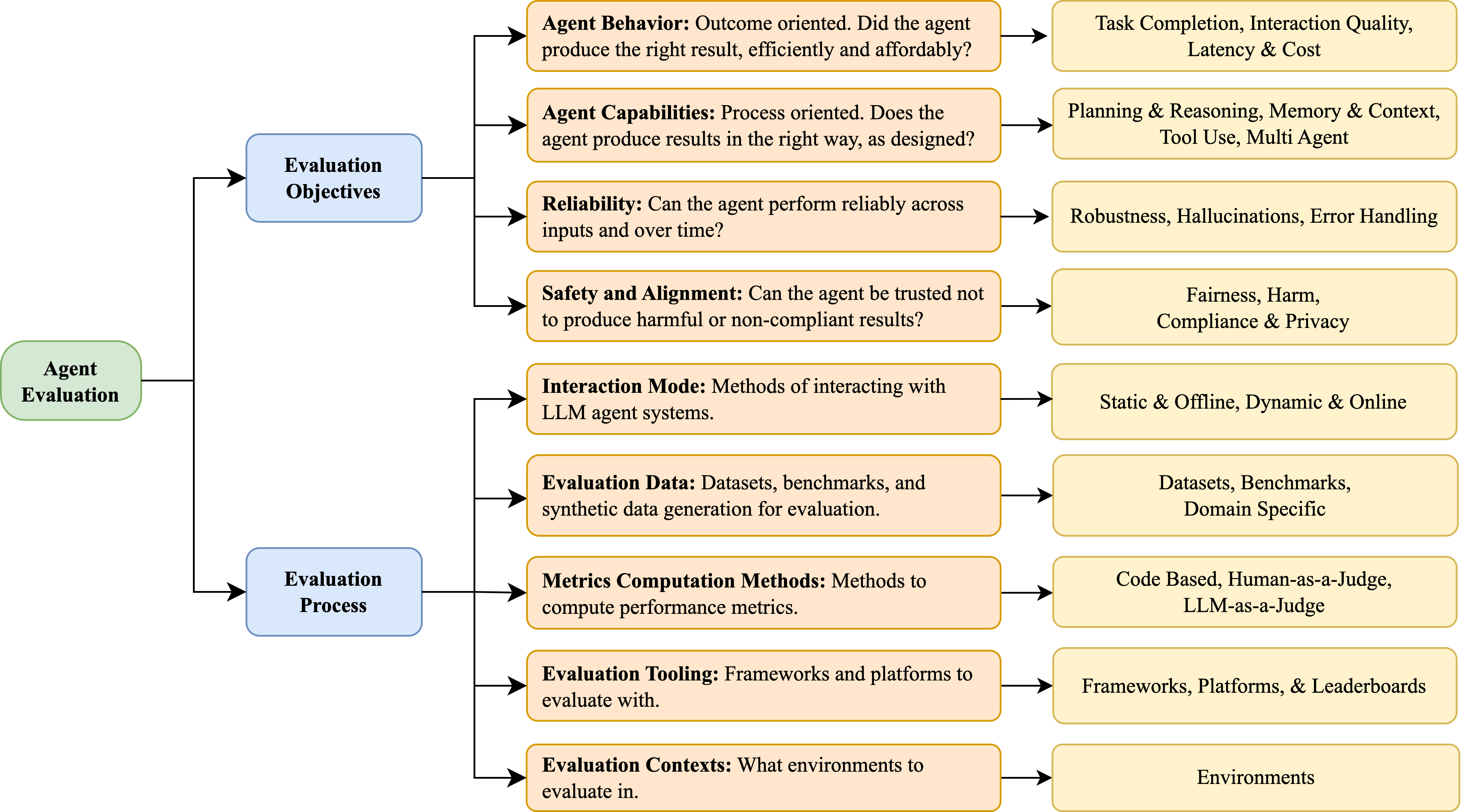
The image depicts a hierarchical flowchart outlining an **Agent Evaluation Framework** for Large Language Model (LLM) systems. It branches into two primary categories: **Evaluation Objectives** (left) and **Evaluation Process** (right), each subdivided into detailed criteria. Arrows indicate relationships between components, emphasizing a structured approach to assessing agent performance.
### Components/Axes
#### Evaluation Objectives (Left Branch)
1. **Agent Behavior**
- Sub-components: Task Completion, Interaction Quality, Latency & Cost
- Question: "Did the agent produce the right result, efficiently and affordably?"
2. **Agent Capabilities**
- Sub-components: Planning & Reasoning, Memory & Context, Tool Use, Multi-Agent
- Question: "Does the agent produce results in the right way, as designed?"
3. **Reliability**
- Sub-components: Robustness, Hallucinations, Error Handling
- Question: "Can the agent perform reliably across inputs and over time?"
4. **Safety and Alignment**
- Sub-components: Fairness, Harm, Compliance & Privacy
- Question: "Can the agent be trusted not to produce harmful or non-compliant results?"
5. **Interaction Mode**
- Sub-components: Static & Offline, Dynamic & Online
- Question: "Methods of interacting with LLM agent systems."
6. **Evaluation Data**
- Sub-components: Datasets, Benchmarks, Domain-Specific
- Description: "Datasets, benchmarks, and synthetic data generation for evaluation."
#### Evaluation Process (Right Branch)
1. **Metrics Computation Methods**
- Sub-components: Code-Based, Human-as-a-Judge, LLM-as-a-Judge
- Description: "Methods to compute performance metrics."
2. **Evaluation Tooling**
- Sub-components: Frameworks, Platforms, & Leaderboards
- Description: "Frameworks and platforms to evaluate with."
3. **Evaluation Contexts**
- Sub-components: Environments
- Description: "What environments to evaluate in."
### Detailed Analysis
- **Agent Behavior** focuses on outcome-oriented metrics (e.g., task completion efficiency).
- **Agent Capabilities** emphasizes process-oriented design adherence (e.g., reasoning, tool use).
- **Reliability** addresses consistency across inputs and time, including error handling.
- **Safety and Alignment** ensures ethical and compliant outputs (e.g., fairness, privacy).
- **Interaction Mode** distinguishes between static/offline and dynamic/online interactions.
- **Evaluation Data** highlights the importance of domain-specific benchmarks.
- **Metrics Computation Methods** include hybrid approaches (human/LLM judges).
- **Evaluation Tooling** and **Contexts** stress the need for scalable frameworks and realistic environments.
### Key Observations
- The framework balances **outcome** (e.g., task completion) and **process** (e.g., reasoning) evaluations.
- **Safety and Alignment** is a standalone pillar, reflecting its criticality in trustworthy AI.
- **Evaluation Data** and **Tooling** components suggest a focus on reproducibility and scalability.
- Arrows indicate a top-down flow: objectives → process → implementation.
### Interpretation
This framework provides a **comprehensive, multi-dimensional evaluation strategy** for LLM agents. By separating objectives (what to measure) from processes (how to measure), it ensures both **effectiveness** (did the agent succeed?) and **reliability** (can it be trusted?). The inclusion of **human/LLM judges** and **domain-specific data** acknowledges the complexity of real-world applications. The emphasis on **safety** and **interaction modes** aligns with ethical AI development trends. Overall, the flowchart advocates for a holistic approach to agent evaluation, critical for deploying robust and responsible LLM systems.