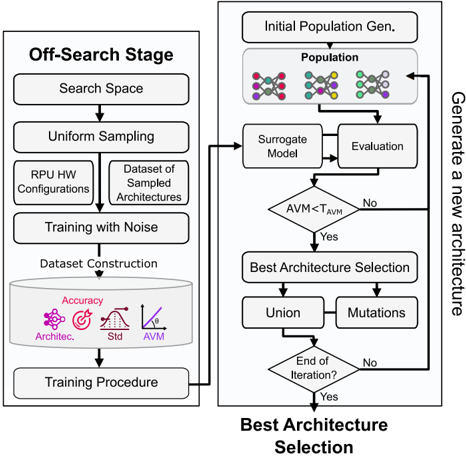
## Flowchart: Architecture Optimization Process
### Overview
The image depicts a two-phase flowchart for optimizing machine learning architectures. The left column outlines the **Off-Search Stage**, involving data generation, training, and evaluation. The right column details the **Best Architecture Selection** phase, focusing on iterative refinement using a surrogate model and evaluation metrics. Arrows indicate the flow of data and decision-making.
### Components/Axes
- **Left Column (Off-Search Stage)**:
- **Search Space**: Defines the range of possible architectures.
- **Uniform Sampling**: Randomly selects architectures from the search space.
- **RPU HW Configurations**: Hardware-specific configurations for training.
- **Dataset of Sampled Architectures**: Curated dataset for training.
- **Training with Noise**: Introduces noise during training to improve robustness.
- **Dataset Construction**: Builds a dataset for evaluation.
- **Training Procedure**: Includes metrics like Accuracy, Std. Dev., and AVM (Architecture Validation Metric).
- **Right Column (Best Architecture Selection)**:
- **Initial Population Gen.**: Generates an initial set of architectures.
- **Surrogate Model**: A model to approximate the performance of architectures.
- **Evaluation**: Assesses architectures using metrics like AVM.
- **Decision Diamond (AVM < T_AVM)**: Compares AVM to a threshold (T_AVM).
- **Best Architecture Selection**: Identifies the optimal architecture.
- **Union & Mutations**: Combines and modifies architectures for refinement.
- **End of Iteration?**: Determines if the process should continue.
- **Legend Colors**: Red, Green, Blue (no explicit legend; colors likely differentiate steps or processes).
### Detailed Analysis
- **Off-Search Stage**:
- **Search Space** → **Uniform Sampling** → **RPU HW Configurations** → **Dataset of Sampled Architectures** → **Training with Noise** → **Dataset Construction** → **Training Procedure**.
- Metrics (Accuracy, Std. Dev., AVM) are visualized in a box labeled "Training Procedure."
- **Best Architecture Selection**:
- **Initial Population Gen.** → **Surrogate Model** → **Evaluation** → **Decision Diamond (AVM < T_AVM)**.
- If **Yes**: **Best Architecture Selection** → **Union** → **Mutations**.
- If **No**: Loop back to **Initial Population Gen.**.
- The process repeats until **End of Iteration?** is "Yes."
### Key Observations
1. **Iterative Refinement**: The flowchart emphasizes a cyclical process where architectures are repeatedly evaluated and refined.
2. **Surrogate Model Use**: The surrogate model reduces computational cost by approximating architecture performance.
3. **Threshold-Based Decision**: The AVM threshold (T_AVM) determines whether an architecture is retained or discarded.
4. **Noise in Training**: Introducing noise during training suggests a focus on generalization and robustness.
### Interpretation
The flowchart represents a hybrid approach combining **evolutionary algorithms** (e.g., genetic operators like Union and Mutations) with **surrogate modeling** for efficient architecture search. The Off-Search Stage focuses on generating diverse architectures, while the Best Architecture Selection phase prioritizes quality through iterative evaluation. The use of AVM as a metric implies a focus on validation accuracy, and the threshold (T_AVM) introduces a trade-off between exploration and exploitation. The absence of a legend for colors is a potential ambiguity, as the red, green, and blue nodes may represent different stages (e.g., training, evaluation, refinement) or data types.
The process highlights the importance of balancing computational efficiency (via surrogate models) with architectural diversity (via mutations and unions) to identify optimal models. The feedback loop ensures continuous improvement, aligning with principles of **Bayesian optimization** or **neural architecture search (NAS)**.