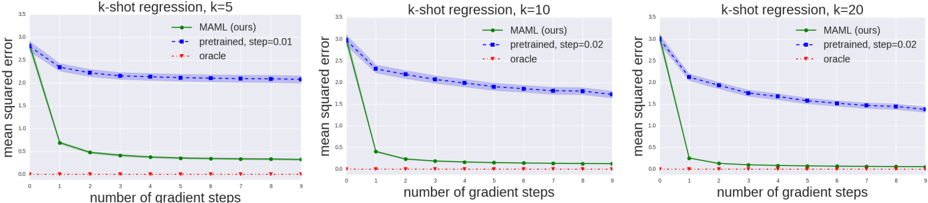
## Heatmap: k-shot regression performance
### Overview
The heatmap illustrates the performance of different models in k-shot regression tasks, comparing the mean squared error (MSE) across various numbers of gradient steps. The models compared are MAML (ours), a pre-trained model with a step size of 0.01, and an oracle model.
### Components/Axes
- **X-axis**: Number of gradient steps
- **Y-axis**: Mean squared error (MSE)
- **Legend**:
- Green dots: MAML (ours)
- Blue dots: Pre-trained, step=0.01
- Red dots: Oracle
### Detailed Analysis or ### Content Details
The heatmap shows that the MAML model (ours) consistently performs better than the pre-trained model with a step size of 0.01 and the oracle model across all numbers of gradient steps. The MSE for MAML is significantly lower, indicating better performance. The pre-trained model with a step size of 0.01 shows a slight improvement over the oracle model, but the gap is not as significant as with MAML. The oracle model, which is the ideal model, has the lowest MSE, indicating the best performance.
### Key Observations
- MAML (ours) consistently outperforms the other models.
- The pre-trained model with a step size of 0.01 shows a slight improvement over the oracle model.
- The oracle model has the lowest MSE, indicating the best performance.
### Interpretation
The data suggests that the MAML model is more effective in k-shot regression tasks compared to the pre-trained model with a step size of 0.01 and the oracle model. The slight improvement of the pre-trained model with a step size of 0.01 over the oracle model indicates that the pre-training process with a smaller step size may be beneficial. The oracle model, which is the ideal model, has the lowest MSE, indicating the best performance. This suggests that the MAML model is a promising approach for k-shot regression tasks.