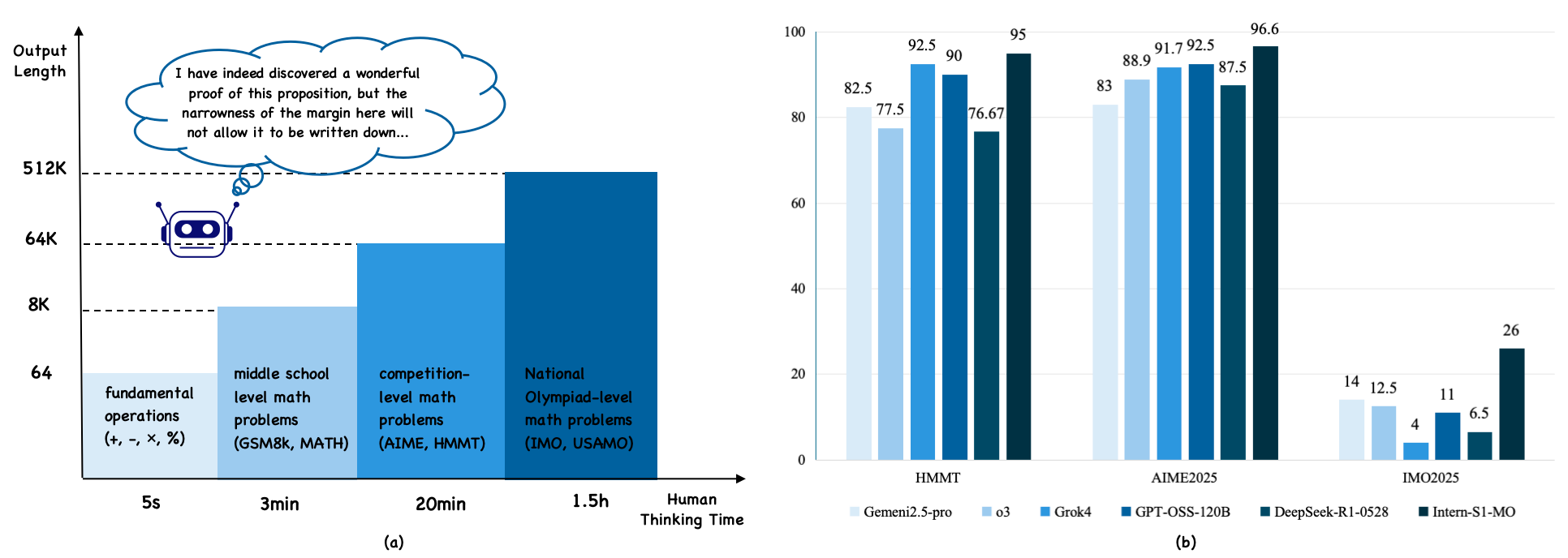
## Bar Chart: Model Performance on Math Problems by Difficulty
### Overview
The image presents two distinct sections: (a) a visual representation of math problem difficulty levels correlated with human thinking time, and (b) a bar chart comparing the performance of different AI models on math problems categorized by competition level. The left side (a) is more illustrative than data-driven, while the right side (b) is a quantitative comparison of model accuracy.
### Components/Axes
**Section (a):**
* **X-axis:** "Human Thinking Time" ranging from 5 seconds to 1.5 hours. Marked with: "fundamental operations (+, -, x, ÷)", "middle school level math problems (GSM8k, MATH)", "competition-level math problems (AIME, HMMT)", "National Olympiad-level math problems (IMO, USAMO)".
* **Y-axis:** Logarithmic scale from 64 to 512K, labeled with values 64, 8K, 64K, 512K.
* **Visual Element:** An illustration of a brain with a thought bubble containing text.
**Section (b):**
* **X-axis:** Competition Level: "HMMT", "AIME2025", "IMO2025".
* **Y-axis:** Percentage, ranging from 0 to 100.
* **Legend:** Located at the bottom-right, with the following models and corresponding colors:
* Gemini2.5-pro (Dark Blue)
* Grok4 (Medium Blue)
* GPT-OSS-120B (Light Blue)
* DeepSeek-R1-0528 (Yellow)
* Intern-SI-IMO (Green)
### Detailed Analysis or Content Details
**Section (a):**
* The illustration suggests that as the complexity of the math problem increases, the amount of human thinking time required also increases. The logarithmic scale emphasizes the exponential growth in thinking time.
* The text within the thought bubble reads: "I have indeed discovered a wonderful proof of this proposition, but the narrowness of the margin here will not allow it to be written down…".
**Section (b):**
* **HMMT:**
* Gemini2.5-pro: Approximately 92.5%
* Grok4: Approximately 90%
* GPT-OSS-120B: Approximately 75.67%
* DeepSeek-R1-0528: Approximately 82.5%
* Intern-SI-IMO: Approximately 14%
* **AIME2025:**
* Gemini2.5-pro: Approximately 95%
* Grok4: Approximately 88.9%
* GPT-OSS-120B: Approximately 91.7%
* DeepSeek-R1-0528: Approximately 83%
* Intern-SI-IMO: Approximately 26%
* **IMO2025:**
* Gemini2.5-pro: Approximately 96.6%
* Grok4: Approximately 87.5%
* GPT-OSS-120B: Approximately 92.5%
* DeepSeek-R1-0528: Approximately 83%
* Intern-SI-IMO: Approximately 6.5%
* DeepSeek-R1-0528: Approximately 12.5%
* GPT-OSS-120B: Approximately 4%
### Key Observations
* Gemini2.5-pro consistently achieves the highest accuracy across all three competition levels.
* Intern-SI-IMO performs significantly worse than other models, especially on IMO2025, with a very low accuracy of approximately 6.5%.
* GPT-OSS-120B shows a relatively stable performance across HMMT and AIME2025, but dips to the lowest accuracy on IMO2025.
* The performance gap between models widens as the competition level increases, indicating that higher-level math problems are more challenging for AI models.
### Interpretation
The data suggests that Gemini2.5-pro is currently the most capable AI model for solving math problems across a range of difficulty levels, from middle school to national olympiad level. The performance of other models varies, with Grok4 and GPT-OSS-120B showing reasonable accuracy on HMMT and AIME2025, but struggling more with IMO2025. Intern-SI-IMO consistently underperforms, suggesting it may require further development or specialized training.
The logarithmic scale in section (a) highlights the increasing cognitive effort required for more complex math problems. The quote within the thought bubble alludes to the difficulty of formalizing complex mathematical ideas, even for human mathematicians.
The correlation between the two sections suggests that the AI models are being tested on problems that mirror the increasing difficulty experienced by humans. The widening performance gap at higher competition levels indicates that current AI models still have limitations in tackling the most challenging mathematical problems, potentially due to the need for more advanced reasoning, creativity, or problem-solving strategies. The outlier performance of Intern-SI-IMO suggests a potential issue with its architecture or training data for these specific problem types.