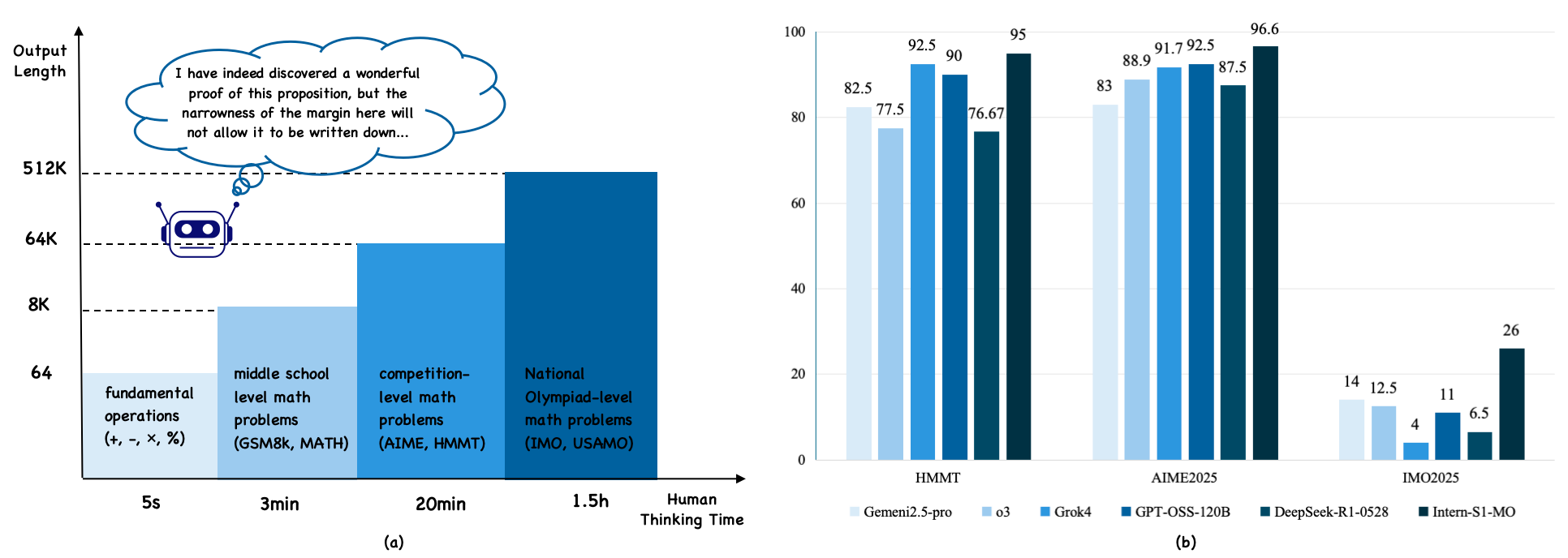
## Diagram: Output Length vs. Thinking Time and Model Performance
### Overview
The image contains two components:
1. **Left Diagram (a)**: A timeline comparing output length (y-axis) against thinking time (x-axis) for different math problem complexities.
2. **Right Bar Chart (b)**: A comparison of model performance (percentage scores) across three math competitions (HMMT, AIME2025, IMO2025) for five AI models.
---
### Components/Axes
#### Diagram (a)
- **Y-Axis**: Output Length (logarithmic scale: 64, 8K, 64K, 512K).
- **X-Axis**: Thinking Time (categories: 5s, 3min, 20min, 1.5h, Human Thinking Time).
- **Legend**:
- Light Blue: Fundamental operations (+, -, ×, %).
- Medium Blue: Middle school level math problems (GSM8k, MATH).
- Dark Blue: Competition-level math problems (AIME, HMMT).
- Very Dark Blue: National Olympiad-level math problems (IMO, USAMO).
- **Text Annotation**: A speech bubble states, *"I have indeed discovered a wonderful proof of this proposition, but the narrowness of the margin here will not allow it to be written down..."*
- **Robot Icon**: Positioned at the 64K output length mark, aligned with the 3min thinking time.
#### Bar Chart (b)
- **X-Axis**: Math Competitions (categories: HMMT, AIME2025, IMO2025).
- **Y-Axis**: Performance Percentage (0–100%).
- **Legend**:
- Light Blue: GPT-4.
- Medium Blue: Grok4.
- Dark Blue: GPT-OSS-120B.
- Very Dark Blue: DeepSeek-R1-0528.
- Black: Intern-S1-MO.
---
### Detailed Analysis
#### Diagram (a)
- **Output Length Trends**:
- **5s**: 64 (fundamental operations).
- **3min**: 8K (middle school problems).
- **20min**: 64K (competition-level problems).
- **1.5h**: 512K (national Olympiad-level problems).
- **Human Thinking Time**: Not explicitly quantified but implied to exceed 1.5h.
#### Bar Chart (b)
- **HMMT Scores**:
- GPT-4: 82.5%
- Grok4: 77.5%
- GPT-OSS-120B: 92.5%
- DeepSeek-R1-0528: 90%
- Intern-S1-MO: 95%
- **AIME2025 Scores**:
- GPT-4: 83%
- Grok4: 88.9%
- GPT-OSS-120B: 91.7%
- DeepSeek-R1-0528: 92.5%
- Intern-S1-MO: 96.6%
- **IMO2025 Scores**:
- GPT-4: 14%
- Grok4: 12.5%
- GPT-OSS-120B: 4%
- DeepSeek-R1-0528: 11%
- Intern-S1-MO: 26%
---
### Key Observations
1. **Diagram (a)**:
- Output length scales exponentially with problem complexity.
- The robot’s thought bubble humorously highlights the impracticality of writing extremely long proofs.
2. **Bar Chart (b)**:
- **AIME2025** and **HMMT** show high performance across models (80–96.6%).
- **IMO2025** scores are significantly lower (4–26%), with Intern-S1-MO outperforming others.
- Intern-S1-MO dominates in **AIME2025** (96.6%) and **IMO2025** (26%), suggesting specialization in advanced problems.
---
### Interpretation
- **Diagram (a)** illustrates the relationship between computational resources (output length) and problem complexity. The exponential growth in output length for Olympiad-level problems underscores the challenges of formalizing human-like reasoning in AI.
- **Bar Chart (b)** reveals that Intern-S1-MO excels in high-stakes competitions, particularly AIME2025, where it achieves near-human performance (96.6%). Its relative weakness in IMO2025 (26%) may reflect dataset biases or problem-specific training gaps.
- **Model Performance**: GPT-OSS-120B and DeepSeek-R1-0528 perform comparably in HMMT and AIME2025, while Intern-S1-MO’s dominance in AIME2025 suggests tailored optimization for competition-level math.
The data highlights the trade-offs between generality and specialization in AI systems, with Intern-S1-MO prioritizing advanced problem-solving at the cost of broader applicability.