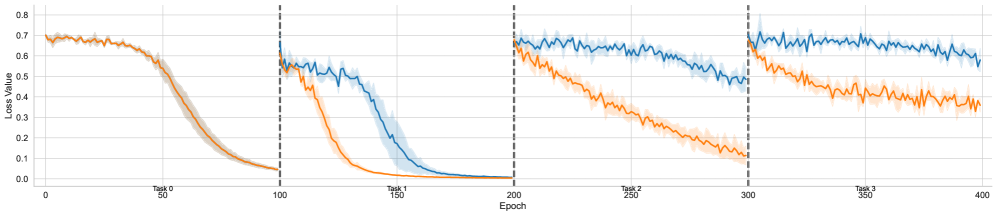
## Line Graph: Loss Value Over Epochs for Three Tasks
### Overview
The image is a line graph depicting the loss value of a model across 400 epochs, divided into three sequential tasks. Each task is represented by a distinct colored line (orange for Task 0, blue for Task 1, and orange for Task 2). Vertical dashed lines at epochs 100, 200, and 300 demarcate the start of each task. The y-axis represents loss value (0.0–0.8), and the x-axis represents epochs (0–400). Shaded regions around the lines indicate variability or confidence intervals.
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch," with ticks at 0, 50, 100, 150, 200, 250, 300, 350, and 400.
- **Y-axis (Loss Value)**: Labeled "Loss Value," with ticks at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, and 0.8.
- **Legend**: Located on the right, with:
- **Orange**: Task 0
- **Blue**: Task 1
- **Orange**: Task 2 (note: Task 0 and Task 2 share the same color, which may cause ambiguity).
- **Vertical Dashed Lines**: At epochs 100 (Task 1 start), 200 (Task 2 start), and 300 (Task 3 start, though only three tasks are labeled).
### Detailed Analysis
1. **Task 0 (Orange Line)**:
- **Trend**: Starts at ~0.7 loss at epoch 0, decreases sharply to ~0.3 by epoch 50, and further drops to ~0.1 by epoch 100. After Task 1 begins (epoch 100), the loss continues to decline gradually to ~0.05 by epoch 200, then plateaus near 0.0.
- **Key Data Points**:
- Epoch 0: ~0.7
- Epoch 50: ~0.3
- Epoch 100: ~0.1
- Epoch 200: ~0.05
- Epoch 400: ~0.0
2. **Task 1 (Blue Line)**:
- **Trend**: Begins at epoch 100 with a loss of ~0.6, decreases to ~0.2 by epoch 150, and further drops to ~0.1 by epoch 200. After Task 2 starts (epoch 200), the loss remains stable at ~0.1 until epoch 400.
- **Key Data Points**:
- Epoch 100: ~0.6
- Epoch 150: ~0.2
- Epoch 200: ~0.1
- Epoch 400: ~0.1
3. **Task 2 (Orange Line)**:
- **Trend**: Starts at epoch 200 with a loss of ~0.6, decreases to ~0.3 by epoch 250, and further drops to ~0.2 by epoch 300. The loss remains relatively stable at ~0.2 from epoch 300 to 400.
- **Key Data Points**:
- Epoch 200: ~0.6
- Epoch 250: ~0.3
- Epoch 300: ~0.2
- Epoch 400: ~0.2
### Key Observations
- **Task 0** shows the steepest initial decline, suggesting rapid learning early in training.
- **Task 1** exhibits a slower, more gradual decline compared to Task 0, with a plateau after epoch 200.
- **Task 2** has the slowest rate of improvement, with a loss reduction of only ~0.4 over 100 epochs (200–300).
- The shared orange color for Tasks 0 and 2 in the legend creates potential confusion, as their trends differ significantly.
- After each task's training period, the loss for prior tasks plateaus, indicating possible catastrophic forgetting or stabilization.
### Interpretation
The graph demonstrates how the model's loss evolves across sequential tasks. Task 0's rapid decline suggests effective initial training, while Task 1 and Task 2 show diminishing returns, possibly due to increased complexity or limited data. The shared orange color for Tasks 0 and 2 in the legend is problematic, as their performance trajectories are distinct. The plateauing of loss values after each task's training period highlights potential challenges in retaining knowledge from prior tasks (catastrophic forgetting). The shaded regions around the lines indicate variability in loss measurements, suggesting uncertainty in the model's performance estimates. Overall, the data underscores the trade-offs between task-specific learning and long-term retention in sequential training scenarios.