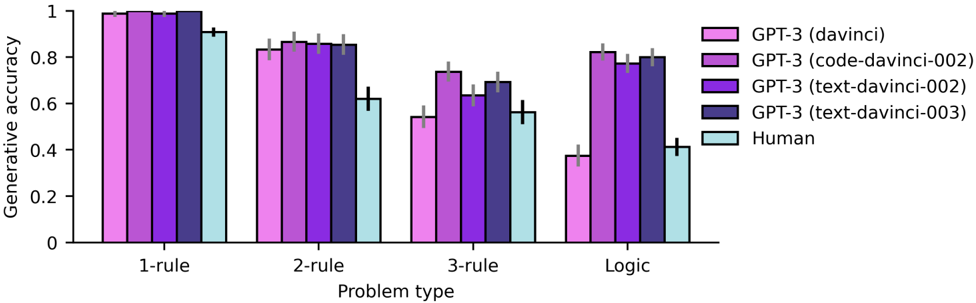
## Bar Chart: Generative Accuracy vs. Problem Type for GPT-3 Models and Humans
### Overview
The image is a bar chart comparing the generative accuracy of different GPT-3 models (davinci, code-davinci-002, text-davinci-002, text-davinci-003) and humans across four problem types: 1-rule, 2-rule, 3-rule, and Logic. The chart displays the accuracy on the y-axis and the problem type on the x-axis. Error bars are included on each bar.
### Components/Axes
* **Y-axis:** "Generative accuracy" with a scale from 0 to 1 in increments of 0.2.
* **X-axis:** "Problem type" with four categories: "1-rule", "2-rule", "3-rule", and "Logic".
* **Legend (Top-Right):**
* Pink: GPT-3 (davinci)
* Light Purple: GPT-3 (code-davinci-002)
* Dark Purple: GPT-3 (text-davinci-002)
* Dark Blue: GPT-3 (text-davinci-003)
* Light Blue: Human
### Detailed Analysis
**1-rule:**
* GPT-3 (davinci) (Pink): Accuracy ~0.99
* GPT-3 (code-davinci-002) (Light Purple): Accuracy ~0.99
* GPT-3 (text-davinci-002) (Dark Purple): Accuracy ~0.99
* GPT-3 (text-davinci-003) (Dark Blue): Accuracy ~0.99
* Human (Light Blue): Accuracy ~0.92
**2-rule:**
* GPT-3 (davinci) (Pink): Accuracy ~0.83
* GPT-3 (code-davinci-002) (Light Purple): Accuracy ~0.85
* GPT-3 (text-davinci-002) (Dark Purple): Accuracy ~0.85
* GPT-3 (text-davinci-003) (Dark Blue): Accuracy ~0.63
* Human (Light Blue): Accuracy ~0.63
**3-rule:**
* GPT-3 (davinci) (Pink): Accuracy ~0.55
* GPT-3 (code-davinci-002) (Light Purple): Accuracy ~0.74
* GPT-3 (text-davinci-002) (Dark Purple): Accuracy ~0.64
* GPT-3 (text-davinci-003) (Dark Blue): Accuracy ~0.64
* Human (Light Blue): Accuracy ~0.57
**Logic:**
* GPT-3 (davinci) (Pink): Accuracy ~0.38
* GPT-3 (code-davinci-002) (Light Purple): Accuracy ~0.79
* GPT-3 (text-davinci-002) (Dark Purple): Accuracy ~0.78
* GPT-3 (text-davinci-003) (Dark Blue): Accuracy ~0.81
* Human (Light Blue): Accuracy ~0.42
### Key Observations
* For the "1-rule" problem type, all GPT-3 models perform nearly perfectly, and slightly better than humans.
* The performance of all models and humans decreases as the problem complexity increases (from 1-rule to 3-rule).
* The "text-davinci-003" model shows a significant drop in accuracy from "1-rule" to "2-rule" problems, and then maintains a relatively stable performance across "3-rule" and "Logic" problems.
* The "davinci" model performs poorly on "Logic" problems compared to other GPT-3 models.
* The "code-davinci-002", "text-davinci-002", and "text-davinci-003" models show relatively similar performance on "2-rule", "3-rule", and "Logic" problems.
* Humans perform relatively consistently across "2-rule", "3-rule", and "Logic" problems, but are outperformed by some GPT-3 models on "Logic" problems.
### Interpretation
The chart illustrates the varying capabilities of different GPT-3 models and humans in solving problems of increasing complexity. The "davinci" model excels at simple tasks but struggles with more complex logic-based problems. The "code-davinci-002", "text-davinci-002", and "text-davinci-003" models demonstrate more consistent performance across different problem types, suggesting a better ability to generalize. The human performance provides a baseline for comparison, highlighting areas where AI models surpass or fall short of human capabilities. The error bars indicate the variability in the results, which should be considered when interpreting the data. The data suggests that model architecture and training data significantly impact the ability of AI models to solve different types of problems.