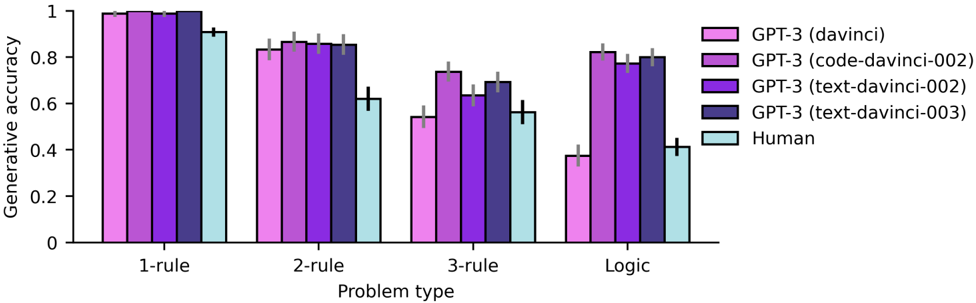
## Grouped Bar Chart: Generative Accuracy by Problem Type and Model
### Overview
The image displays a grouped bar chart comparing the generative accuracy of four different GPT-3 model variants and human performance across four categories of problem complexity. The chart illustrates how accuracy changes as the problem type increases in complexity from single-rule to logic-based tasks.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **Y-Axis:** Labeled "Generative accuracy". The scale runs from 0 to 1, with major tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **X-Axis:** Labeled "Problem type". It contains four categorical groups: "1-rule", "2-rule", "3-rule", and "Logic".
* **Legend:** Located in the top-right corner of the chart area. It defines five data series with corresponding colors:
* GPT-3 (davinci): Light pink/magenta
* GPT-3 (code-davinci-002): Medium purple
* GPT-3 (text-davinci-002): Dark purple
* GPT-3 (text-davinci-003): Very dark purple/indigo
* Human: Light blue/cyan
* **Error Bars:** Each bar includes a vertical black error bar extending above and below the top of the bar, indicating variability or confidence intervals in the measurements.
### Detailed Analysis
The chart is segmented into four problem type groups. Each group contains five bars, ordered from left to right as per the legend: GPT-3 (davinci), GPT-3 (code-davinci-002), GPT-3 (text-davinci-002), GPT-3 (text-davinci-003), and Human.
**1. 1-rule Problems:**
* **Trend:** All models and humans achieve very high accuracy, near the maximum value.
* **Approximate Values (with uncertainty):**
* GPT-3 (davinci): ~0.98
* GPT-3 (code-davinci-002): ~0.99
* GPT-3 (text-davinci-002): ~0.99
* GPT-3 (text-davinci-003): ~0.99
* Human: ~0.90 (slightly lower than the models)
**2. 2-rule Problems:**
* **Trend:** A general decrease in accuracy compared to 1-rule problems for all entities. The GPT-3 models remain clustered together, while human performance shows a more pronounced drop.
* **Approximate Values (with uncertainty):**
* GPT-3 (davinci): ~0.83
* GPT-3 (code-davinci-002): ~0.86
* GPT-3 (text-davinci-002): ~0.85
* GPT-3 (text-davinci-003): ~0.85
* Human: ~0.62
**3. 3-rule Problems:**
* **Trend:** A further decline in accuracy. The performance gap between the GPT-3 models widens slightly, and human accuracy continues to fall.
* **Approximate Values (with uncertainty):**
* GPT-3 (davinci): ~0.55
* GPT-3 (code-davinci-002): ~0.73
* GPT-3 (text-davinci-002): ~0.64
* GPT-3 (text-davinci-003): ~0.69
* Human: ~0.56
**4. Logic Problems:**
* **Trend:** This category shows the lowest overall accuracy and the greatest variance between models. GPT-3 (davinci) performs significantly worse than the other models. Human performance is comparable to the lowest-performing model in this category.
* **Approximate Values (with uncertainty):**
* GPT-3 (davinci): ~0.38
* GPT-3 (code-davinci-002): ~0.82
* GPT-3 (text-davinci-002): ~0.77
* GPT-3 (text-davinci-003): ~0.80
* Human: ~0.41
### Key Observations
1. **Inverse Relationship with Complexity:** There is a clear inverse relationship between problem complexity (number of rules/logic) and generative accuracy for all tested entities. Accuracy is highest for "1-rule" problems and lowest for "Logic" problems.
2. **Model Consistency on Rule-Based Tasks:** For rule-based problems (1, 2, and 3-rule), the four GPT-3 model variants perform relatively similarly, with accuracy scores clustered within a ~0.15 range for each category.
3. **Divergence on Logic Tasks:** The "Logic" problem type causes a significant divergence in model performance. GPT-3 (davinci) shows a dramatic drop in accuracy, while the other three models (code-davinci-002, text-davinci-002, text-davinci-003) maintain relatively high accuracy (~0.77-0.82).
4. **Human vs. Model Performance:** Humans outperform all models only in the "1-rule" category (though models are very close). For "2-rule" and "3-rule" problems, the GPT-3 models consistently outperform humans. In "Logic" problems, human performance (~0.41) is comparable to the lowest-performing model (GPT-3 davinci, ~0.38) but significantly below the other models.
### Interpretation
The data suggests that the ability to generate accurate solutions degrades as the underlying problem structure becomes more complex, involving multiple rules or abstract logic. This is a common challenge in both human and machine reasoning.
The consistent performance of the GPT-3 models on rule-based tasks indicates a strong capability for pattern application when the rules are explicit. The significant drop for GPT-3 (davinci) on logic problems, contrasted with the resilience of the later models (code-davinci-002, text-davinci-002/003), highlights a potential advancement in the later models' training or architecture that improves their capacity for logical reasoning or handling more abstract problem spaces.
The human performance curve—starting high but dropping more steeply than most models on rule-based tasks—might reflect different cognitive strategies. Humans may excel at simple, direct rule application but find the systematic application of multiple, potentially interacting rules more taxing than the models, which are optimized for such pattern-based tasks. The convergence of human and the weakest model's performance on logic problems suggests that this category represents a fundamental challenge for both biological and artificial intelligence as configured in this test.