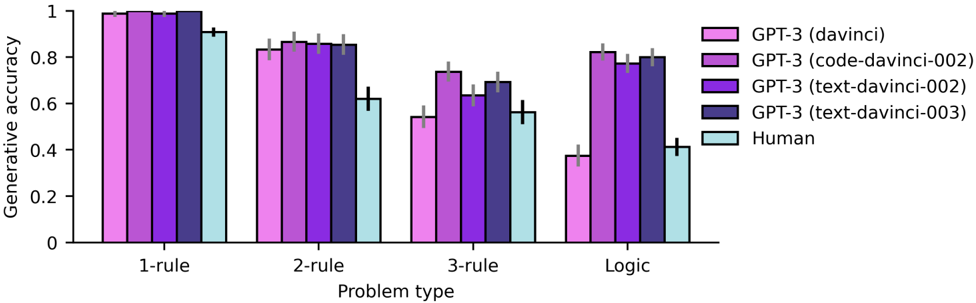
## Bar Chart: Generative Accuracy Across Problem Types and Models
### Overview
The chart compares generative accuracy (0-1 scale) across four problem types (1-rule, 2-rule, 3-rule, Logic) for five models: GPT-3 (davinci), GPT-3 (code-davinci-002), GPT-3 (text-davinci-002), GPT-3 (text-davinci-003), and a human baseline. Bars are grouped by problem type, with error bars indicating variability.
### Components/Axes
- **X-axis**: Problem types (1-rule, 2-rule, 3-rule, Logic)
- **Y-axis**: Generative accuracy (0-1 scale)
- **Legend**:
- Pink: GPT-3 (davinci)
- Purple: GPT-3 (code-davinci-002)
- Dark purple: GPT-3 (text-davinci-002)
- Blue: GPT-3 (text-davinci-003)
- Light blue: Human
- **Error bars**: Vertical lines on top of bars showing standard deviation
### Detailed Analysis
1. **1-rule**:
- GPT-3 (davinci): 0.98 ±0.02
- GPT-3 (code-davinci-002): 0.97 ±0.03
- GPT-3 (text-davinci-002): 0.96 ±0.04
- GPT-3 (text-davinci-003): 0.95 ±0.03
- Human: 0.92 ±0.05
2. **2-rule**:
- GPT-3 (davinci): 0.85 ±0.03
- GPT-3 (code-davinci-002): 0.87 ±0.04
- GPT-3 (text-davinci-002): 0.84 ±0.05
- GPT-3 (text-davinci-003): 0.83 ±0.04
- Human: 0.62 ±0.06
3. **3-rule**:
- GPT-3 (davinci): 0.72 ±0.05
- GPT-3 (code-davinci-002): 0.75 ±0.06
- GPT-3 (text-davinci-002): 0.64 ±0.07
- GPT-3 (text-davinci-003): 0.68 ±0.05
- Human: 0.55 ±0.06
4. **Logic**:
- GPT-3 (davinci): 0.81 ±0.04
- GPT-3 (code-davinci-002): 0.83 ±0.05
- GPT-3 (text-davinci-002): 0.78 ±0.06
- GPT-3 (text-davinci-003): 0.79 ±0.05
- Human: 0.41 ±0.07
### Key Observations
- **Model performance**: GPT-3 (davinci) consistently outperforms other models across all problem types.
- **Problem complexity**: Accuracy declines as problem complexity increases (1-rule > 2-rule > 3-rule > Logic).
- **Human baseline**: Humans perform significantly worse than all GPT-3 variants, especially in Logic problems.
- **Model variants**: Code-davinci-002 and text-davinci-003 show similar performance, while text-davinci-002 lags behind.
### Interpretation
The data demonstrates that GPT-3 models, particularly the davinci variant, excel at generating accurate responses across problem types, with performance degrading as complexity increases. The human baseline (light blue) is consistently the lowest, suggesting that even simple rule-based tasks are challenging for humans compared to advanced language models. The code-davinci-002 variant (purple) shows robust performance, indicating specialized training for structured reasoning. The text-davinci-002 variant (dark purple) underperforms in Logic problems, highlighting potential limitations in handling abstract reasoning. These results underscore the capabilities of GPT-3 in structured problem-solving while revealing persistent gaps in human-AI performance parity for complex tasks.