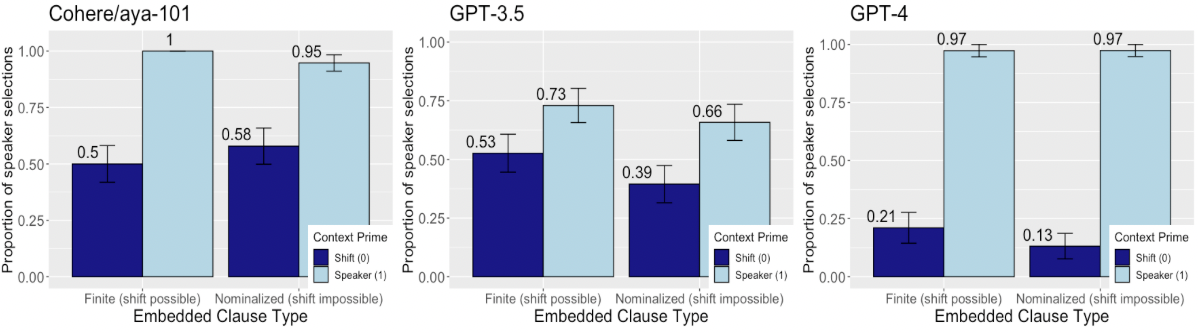
## Bar Chart: Proportion of Speaker Selections by Embedded Clause Type and Model
### Overview
The image presents three bar charts comparing the proportion of speaker selections for different embedded clause types ("Finite (shift possible)" and "Nominalized (shift impossible)") across three language models: Cohere/aya-101, GPT-3.5, and GPT-4. The charts show the proportion of speaker selections for two context primes: "Shift (0)" (dark blue) and "Speaker (1)" (light blue). Error bars are included on each bar.
### Components/Axes
* **Titles:**
* Chart 1 (left): "Cohere/aya-101"
* Chart 2 (center): "GPT-3.5"
* Chart 3 (right): "GPT-4"
* **Y-axis:** "Proportion of speaker selections"
* Scale: 0.00 to 1.00, with increments of 0.25.
* **X-axis:** "Embedded Clause Type"
* Categories: "Finite (shift possible)" and "Nominalized (shift impossible)"
* **Legend:** Located at the bottom-center of the image, applies to all three charts.
* "Context Prime"
* "Shift (0)": Dark blue
* "Speaker (1)": Light blue
### Detailed Analysis
**Chart 1: Cohere/aya-101**
* **Finite (shift possible):**
* Shift (0) (dark blue): Approximately 0.50
* Speaker (1) (light blue): Approximately 1.00
* **Nominalized (shift impossible):**
* Shift (0) (dark blue): Approximately 0.58
* Speaker (1) (light blue): Approximately 0.95
**Chart 2: GPT-3.5**
* **Finite (shift possible):**
* Shift (0) (dark blue): Approximately 0.53
* Speaker (1) (light blue): Approximately 0.73
* **Nominalized (shift impossible):**
* Shift (0) (dark blue): Approximately 0.39
* Speaker (1) (light blue): Approximately 0.66
**Chart 3: GPT-4**
* **Finite (shift possible):**
* Shift (0) (dark blue): Approximately 0.21
* Speaker (1) (light blue): Approximately 0.97
* **Nominalized (shift impossible):**
* Shift (0) (dark blue): Approximately 0.13
* Speaker (1) (light blue): Approximately 0.97
### Key Observations
* Across all models, the "Speaker (1)" context prime (light blue) consistently shows a higher proportion of speaker selections compared to the "Shift (0)" context prime (dark blue).
* For Cohere/aya-101, the "Speaker (1)" context prime reaches nearly 1.0 for both embedded clause types.
* GPT-4 shows the most significant difference between "Shift (0)" and "Speaker (1)" context primes, with "Shift (0)" being very low for both embedded clause types.
* The error bars appear to be relatively small, suggesting consistent results.
### Interpretation
The data suggests that all three language models are more likely to select the speaker when the context prime is "Speaker (1)" compared to "Shift (0)". This indicates a bias towards maintaining the current speaker in the generated text. Cohere/aya-101 exhibits the strongest bias towards the speaker, while GPT-4 shows the most pronounced difference between the two context primes. The difference in performance between the models may reflect differences in their training data, architecture, or fine-tuning strategies. The embedded clause type ("Finite" vs. "Nominalized") appears to have a relatively small impact on the proportion of speaker selections compared to the context prime.