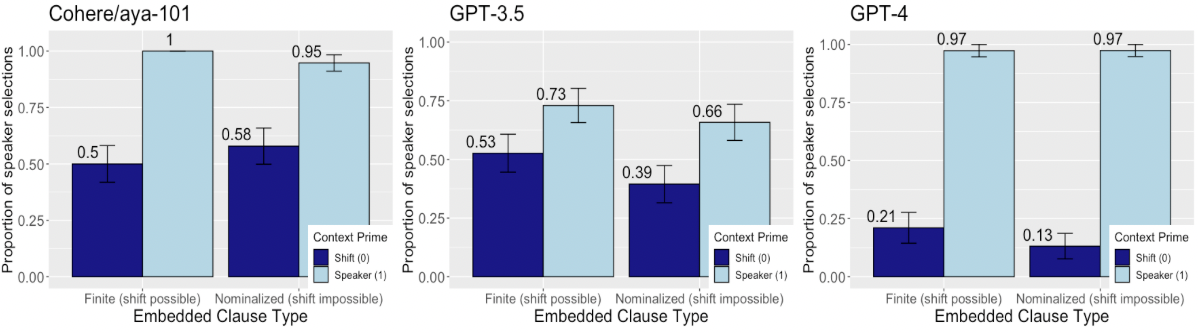
## Bar Charts: Comparison of Speaker Selection Proportions Across AI Models
### Overview
The image displays three side-by-side bar charts comparing the performance of three AI models—Cohere/aya-101, GPT-3.5, and GPT-4—on a speaker selection task. The task measures the proportion of times the model selects a specific speaker ("Speaker (1)") versus a shifted reference ("Shift (0)") based on the type of embedded clause in the prompt. Each chart corresponds to one model and contains two pairs of bars.
### Components/Axes
* **Chart Layout:** Three separate bar charts arranged horizontally.
* **Common Y-Axis (All Charts):** Label: "Proportion of speaker selections". Scale: 0.00 to 1.00, with major ticks at 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Common X-Axis (All Charts):** Label: "Embedded Clause Type". Categories: "Finite (shift possible)" and "Nominalized (shift impossible)".
* **Common Legend (All Charts):** Located in the bottom-right corner of each chart. Title: "Context Prime". Categories:
* Dark Blue Bar: "Shift (0)"
* Light Blue Bar: "Speaker (1)"
* **Data Labels:** Numerical values are printed directly above each bar.
* **Error Bars:** Each bar has a black error bar indicating variability (likely standard error or confidence interval).
### Detailed Analysis
**Chart 1: Cohere/aya-101 (Left)**
* **Finite (shift possible):**
* Shift (0) [Dark Blue]: Value = 0.5. Error bar spans approximately 0.45 to 0.55.
* Speaker (1) [Light Blue]: Value = 1.0. Error bar is very small, near the top of the bar.
* **Nominalized (shift impossible):**
* Shift (0) [Dark Blue]: Value = 0.58. Error bar spans approximately 0.53 to 0.63.
* Speaker (1) [Light Blue]: Value = 0.95. Error bar spans approximately 0.92 to 0.98.
* **Trend:** For both clause types, the "Speaker (1)" selection proportion is significantly higher than the "Shift (0)" proportion. The model shows near-perfect selection of "Speaker (1)" for finite clauses.
**Chart 2: GPT-3.5 (Center)**
* **Finite (shift possible):**
* Shift (0) [Dark Blue]: Value = 0.53. Error bar spans approximately 0.48 to 0.58.
* Speaker (1) [Light Blue]: Value = 0.73. Error bar spans approximately 0.68 to 0.78.
* **Nominalized (shift impossible):**
* Shift (0) [Dark Blue]: Value = 0.39. Error bar spans approximately 0.34 to 0.44.
* Speaker (1) [Light Blue]: Value = 0.66. Error bar spans approximately 0.61 to 0.71.
* **Trend:** Similar to Cohere, "Speaker (1)" is selected more often than "Shift (0)" for both clause types. However, the overall proportions for "Speaker (1)" are lower than Cohere's, and the gap between the two conditions is smaller for nominalized clauses.
**Chart 3: GPT-4 (Right)**
* **Finite (shift possible):**
* Shift (0) [Dark Blue]: Value = 0.21. Error bar spans approximately 0.16 to 0.26.
* Speaker (1) [Light Blue]: Value = 0.97. Error bar is very small, near the top of the bar.
* **Nominalized (shift impossible):**
* Shift (0) [Dark Blue]: Value = 0.13. Error bar spans approximately 0.08 to 0.18.
* Speaker (1) [Light Blue]: Value = 0.97. Error bar is very small, near the top of the bar.
* **Trend:** GPT-4 shows a very strong and consistent bias towards selecting "Speaker (1)" for both clause types, with proportions near 1.0. Conversely, the selection of "Shift (0)" is very low for both conditions, and even lower for nominalized clauses.
### Key Observations
1. **Model Performance Hierarchy:** GPT-4 demonstrates the strongest and most consistent preference for "Speaker (1)" selection (≈0.97 for both conditions). Cohere/aya-101 shows a strong preference but with more variation between clause types (1.0 vs. 0.95). GPT-3.5 shows the weakest preference and the most sensitivity to clause type.
2. **Effect of Clause Type:** For Cohere and GPT-3.5, the "Shift (0)" selection proportion changes notably between Finite and Nominalized clauses (Cohere: 0.5 -> 0.58; GPT-3.5: 0.53 -> 0.39). For GPT-4, the effect is minimal (0.21 -> 0.13).
3. **Error Bar Consistency:** The error bars for the "Speaker (1)" condition in Cohere (Finite) and GPT-4 (both) are extremely small, suggesting high model consistency or low variance in those specific measurements. Error bars are generally larger for the "Shift (0)" condition.
4. **Anomaly:** GPT-3.5's "Shift (0)" proportion for the Nominalized condition (0.39) is lower than its proportion for the Finite condition (0.53), which is the opposite trend compared to Cohere (0.5 -> 0.58).
### Interpretation
This data suggests a significant difference in how these language models handle reference and perspective shift in embedded clauses. The "Speaker (1)" condition likely represents a default or correct coreference resolution, while "Shift (0)" represents a more complex, context-dependent shift.
* **GPT-4** appears to have a robust, almost unwavering mechanism for selecting the direct speaker reference, largely unaffected by the grammatical structure (finite vs. nominalized) that enables or prevents a shift. This indicates a strong prior for the most salient entity.
* **Cohere/aya-101** also strongly favors the speaker reference but shows a slight increase in "Shift (0)" selections when a shift is grammatically impossible (nominalized), which is a subtle but interesting behavioral quirk.
* **GPT-3.5** is the most sensitive to the linguistic cue. Its lower overall "Speaker (1)" scores and the reversal in the "Shift (0)" trend between clause types suggest its coreference resolution is more variable and more influenced by syntactic constraints. The drop in "Shift (0)" for nominalized clauses might indicate confusion or a different processing strategy when a shift is explicitly blocked.
In summary, the charts reveal a progression in model behavior: from GPT-3.5's syntactically-sensitive and variable performance, to Cohere's strong but slightly context-influenced performance, to GPT-4's dominant and context-invariant preference for the primary speaker reference. This has implications for understanding model reliability in tasks requiring nuanced perspective-taking or handling of complex syntactic structures.