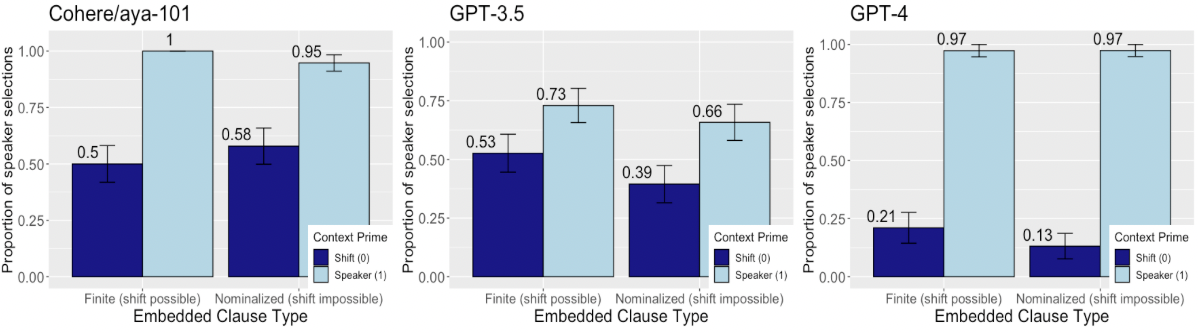
## Bar Chart: Proportion of Speaker Selections Across Models and Clause Types
### Overview
The image presents three grouped bar charts comparing the proportion of speaker selections (vs. shift selections) across three language models: Cohere/aya-101, GPT-3.5, and GPT-4. Each chart evaluates two embedded clause types: "Finite (shift possible)" and "Nominalized (shift impossible)". The y-axis represents the proportion of speaker selections (0–1.0), while the x-axis categorizes clause types. A legend distinguishes "Shift (0)" (dark blue) and "Speaker (1)" (light blue) selections.
### Components/Axes
- **X-Axis (Embedded Clause Type)**:
- "Finite (shift possible)" (left)
- "Nominalized (shift impossible)" (right)
- **Y-Axis (Proportion of Speaker Selections)**:
- Scale: 0.00 to 1.00 in increments of 0.25
- **Legend**:
- Positioned in the bottom-left corner of all charts
- "Shift (0)": Dark blue bars
- "Speaker (1)": Light blue bars
- **Models**:
- Cohere/aya-101 (leftmost chart)
- GPT-3.5 (middle chart)
- GPT-4 (rightmost chart)
### Detailed Analysis
#### Cohere/aya-101
- **Finite (shift possible)**:
- Shift (0): 0.50 (±0.05)
- Speaker (1): 1.00 (±0.00)
- **Nominalized (shift impossible)**:
- Shift (0): 0.58 (±0.05)
- Speaker (1): 0.95 (±0.05)
#### GPT-3.5
- **Finite (shift possible)**:
- Shift (0): 0.53 (±0.05)
- Speaker (1): 0.73 (±0.05)
- **Nominalized (shift impossible)**:
- Shift (0): 0.39 (±0.05)
- Speaker (1): 0.66 (±0.05)
#### GPT-4
- **Finite (shift possible)**:
- Shift (0): 0.21 (±0.05)
- Speaker (1): 0.97 (±0.05)
- **Nominalized (shift impossible)**:
- Shift (0): 0.13 (±0.05)
- Speaker (1): 0.97 (±0.05)
### Key Observations
1. **Model Performance Trends**:
- GPT-4 demonstrates the highest speaker selection proportions (0.97) for both clause types, outperforming GPT-3.5 (0.73/0.66) and Cohere/aya-101 (1.00/0.95).
- Cohere/aya-101 shows perfect speaker selection (1.00) for finite clauses but slightly lower performance (0.95) for nominalized clauses.
- GPT-3.5 exhibits the largest disparity between clause types (0.73 vs. 0.66), suggesting reduced reliability in nominalized contexts.
2. **Clause Type Impact**:
- Nominalized clauses (shift impossible) consistently show lower speaker selection proportions than finite clauses across all models.
- GPT-4’s near-identical performance (0.97) for both clause types implies robustness to shift constraints.
3. **Uncertainty**:
- Error bars (±0.05) indicate moderate variability in speaker selection proportions, particularly for GPT-3.5 and Cohere/aya-101.
### Interpretation
The data suggests that language models generally favor speaker selections over shift selections, with performance varying by model architecture and clause structure. GPT-4’s high and consistent proportions (0.97) across both clause types indicate superior handling of embedded clauses, potentially due to advanced contextual understanding. The decline in speaker selection for nominalized clauses (e.g., GPT-3.5: 0.73 → 0.66) highlights challenges in processing shift-impossible structures. Cohere/aya-101’s perfect finite clause performance (1.00) may reflect specialized training for simpler syntactic contexts. These findings underscore the importance of model architecture and training data in resolving embedded clause ambiguities.