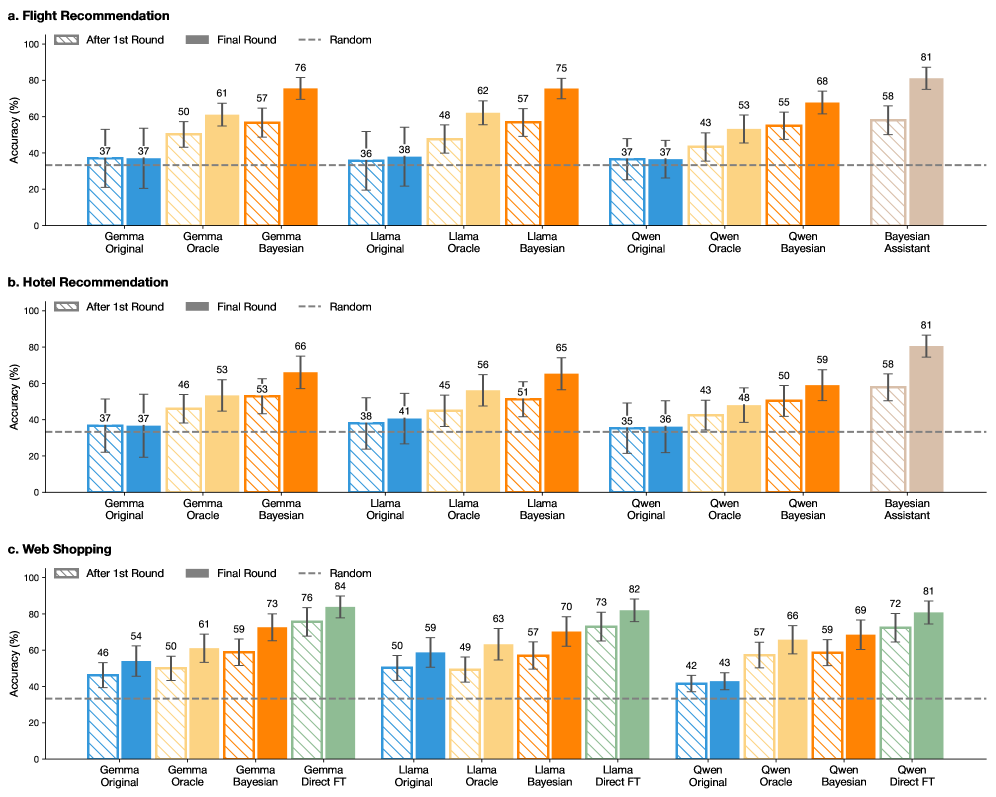
## Bar Chart: Recommendation Accuracy Comparison
### Overview
The image presents three bar charts comparing the accuracy of different recommendation systems (Gemma, Llama, Qwen, and Bayesian Assistant/Direct FT) across three scenarios: Flight Recommendation, Hotel Recommendation, and Web Shopping. The charts compare the accuracy after the first round, in the final round, and against a random baseline.
### Components/Axes
* **Chart Titles:**
* a. Flight Recommendation
* b. Hotel Recommendation
* c. Web Shopping
* **Y-Axis:**
* Label: Accuracy (%)
* Scale: 0 to 100, with tick marks at intervals of 20.
* **X-Axis:**
* Categories: Gemma, Llama, Qwen, Bayesian Assistant/Direct FT
* Sub-categories: Original, Oracle, Bayesian, Direct FT (where applicable)
* **Legend:** Located at the top-left of each chart.
* After 1st Round (Blue)
* Final Round (Yellow/Orange)
* Random (Gray/Green with diagonal lines)
* **Horizontal Dashed Line:** Represents the "Random" baseline accuracy.
### Detailed Analysis
#### a. Flight Recommendation
* **Gemma Original:**
* After 1st Round: 37%
* Final Round: 37%
* **Gemma Oracle:**
* After 1st Round: 50%
* Final Round: 61%
* **Gemma Bayesian:**
* After 1st Round: 57%
* Final Round: 76%
* Random: 57%
* **Llama Original:**
* After 1st Round: 36%
* Final Round: 38%
* **Llama Oracle:**
* After 1st Round: 48%
* Final Round: 62%
* **Llama Bayesian:**
* After 1st Round: 57%
* Final Round: 75%
* Random: 57%
* **Qwen Original:**
* After 1st Round: 37%
* Final Round: 37%
* **Qwen Oracle:**
* After 1st Round: 43%
* Final Round: 53%
* **Qwen Bayesian:**
* After 1st Round: 55%
* Final Round: 68%
* Random: 55%
* **Bayesian Assistant:**
* Random: 81%
#### b. Hotel Recommendation
* **Gemma Original:**
* After 1st Round: 37%
* Final Round: 37%
* **Gemma Oracle:**
* After 1st Round: 46%
* Final Round: 53%
* **Gemma Bayesian:**
* After 1st Round: 53%
* Final Round: 66%
* Random: 53%
* **Llama Original:**
* After 1st Round: 38%
* Final Round: 41%
* **Llama Oracle:**
* After 1st Round: 45%
* Final Round: 56%
* **Llama Bayesian:**
* After 1st Round: 51%
* Final Round: 65%
* Random: 51%
* **Qwen Original:**
* After 1st Round: 35%
* Final Round: 36%
* **Qwen Oracle:**
* After 1st Round: 43%
* Final Round: 48%
* **Qwen Bayesian:**
* After 1st Round: 50%
* Final Round: 59%
* Random: 50%
* **Bayesian Assistant:**
* Random: 81%
#### c. Web Shopping
* **Gemma Original:**
* After 1st Round: 46%
* Final Round: 54%
* **Gemma Oracle:**
* After 1st Round: 50%
* Final Round: 61%
* **Gemma Bayesian:**
* After 1st Round: 59%
* Final Round: 73%
* Random: 59%
* **Gemma Direct FT:**
* Random: 84%
* **Llama Original:**
* After 1st Round: 50%
* Final Round: 59%
* **Llama Oracle:**
* After 1st Round: 49%
* Final Round: 63%
* **Llama Bayesian:**
* After 1st Round: 57%
* Final Round: 70%
* Random: 57%
* **Llama Direct FT:**
* Random: 82%
* **Qwen Original:**
* After 1st Round: 42%
* Final Round: 43%
* **Qwen Oracle:**
* After 1st Round: 57%
* Final Round: 66%
* **Qwen Bayesian:**
* After 1st Round: 59%
* Final Round: 69%
* Random: 59%
* **Qwen Direct FT:**
* Random: 81%
### Key Observations
* In general, the "Final Round" accuracy is higher than the "After 1st Round" accuracy for most models and scenarios.
* The "Bayesian Assistant" (for Flight and Hotel Recommendations) and "Direct FT" (for Web Shopping) models consistently show the highest accuracy compared to other models.
* The "Original" models (Gemma Original, Llama Original, Qwen Original) tend to have the lowest accuracy.
* The random baseline accuracy varies across the different recommendation tasks.
### Interpretation
The data suggests that refining recommendation models over multiple rounds generally improves their accuracy. The Bayesian Assistant and Direct FT models appear to be the most effective for these tasks, indicating that incorporating Bayesian methods or direct fine-tuning can significantly enhance recommendation performance. The lower accuracy of the "Original" models highlights the importance of optimization and refinement in recommendation systems. The varying random baselines indicate that the difficulty of the recommendation task differs across the three scenarios (Flight, Hotel, Web Shopping).