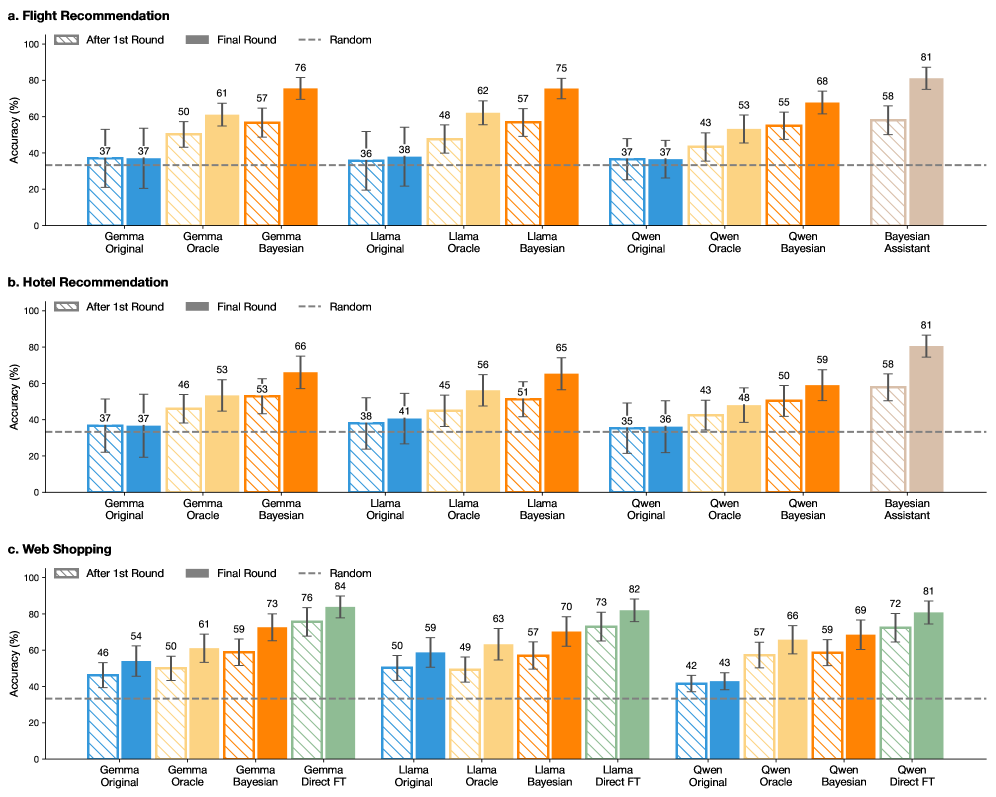
\n
## Bar Chart: Model Performance Across Tasks and Strategies
### Overview
The image presents three bar charts (a, b, and c), each comparing the performance of different language models (Gemma Original, Gemma Oracle, Gemma Bayesian, Llama Original, Llama Oracle, Llama Bayesian, Owen Original, Owen Oracle, Owen Bayesian, and Bayesian Assistant) across three strategies: "After 1st Round", "Final Round", and "Random". The charts evaluate performance on three distinct tasks: "Flight Recommendation", "Hotel Recommendation", and "Web Shopping". Performance is measured by "Accuracy (%)". Error bars are included for each data point, indicating variability.
### Components/Axes
* **X-axis:** Represents the different language models used for each task.
* **Y-axis:** Represents the accuracy percentage, ranging from 0 to 100. The axis is labeled "Accuracy (%)".
* **Bar Colors:**
* "After 1st Round": Dark Blue
* "Final Round": Purple
* "Random": Light Gray
* **Tasks:**
* a. Flight Recommendation
* b. Hotel Recommendation
* c. Web Shopping
* **Models:** Gemma Original, Gemma Oracle, Gemma Bayesian, Llama Original, Llama Oracle, Llama Bayesian, Owen Original, Owen Oracle, Owen Bayesian, Bayesian Assistant, Direct FT (only in Web Shopping)
### Detailed Analysis or Content Details
**a. Flight Recommendation**
* **Gemma Original:** After 1st Round: ~37%, Final Round: ~50%, Random: ~37%
* **Gemma Oracle:** After 1st Round: ~37%, Final Round: ~61%, Random: ~37%
* **Gemma Bayesian:** After 1st Round: ~37%, Final Round: ~76%, Random: ~36%
* **Llama Original:** After 1st Round: ~38%, Final Round: ~48%, Random: ~38%
* **Llama Oracle:** After 1st Round: ~38%, Final Round: ~62%, Random: ~38%
* **Llama Bayesian:** After 1st Round: ~38%, Final Round: ~75%, Random: ~38%
* **Owen Original:** After 1st Round: ~37%, Final Round: ~43%, Random: ~37%
* **Owen Oracle:** After 1st Round: ~37%, Final Round: ~55%, Random: ~37%
* **Owen Bayesian:** After 1st Round: ~37%, Final Round: ~68%, Random: ~37%
* **Bayesian Assistant:** After 1st Round: ~37%, Final Round: ~81%, Random: ~37%
**b. Hotel Recommendation**
* **Gemma Original:** After 1st Round: ~37%, Final Round: ~46%, Random: ~38%
* **Gemma Oracle:** After 1st Round: ~37%, Final Round: ~53%, Random: ~38%
* **Gemma Bayesian:** After 1st Round: ~37%, Final Round: ~66%, Random: ~38%
* **Llama Original:** After 1st Round: ~41%, Final Round: ~45%, Random: ~41%
* **Llama Oracle:** After 1st Round: ~41%, Final Round: ~56%, Random: ~41%
* **Llama Bayesian:** After 1st Round: ~41%, Final Round: ~65%, Random: ~41%
* **Owen Original:** After 1st Round: ~36%, Final Round: ~43%, Random: ~36%
* **Owen Oracle:** After 1st Round: ~36%, Final Round: ~50%, Random: ~36%
* **Owen Bayesian:** After 1st Round: ~36%, Final Round: ~59%, Random: ~36%
* **Bayesian Assistant:** After 1st Round: ~36%, Final Round: ~81%, Random: ~36%
**c. Web Shopping**
* **Gemma Original:** After 1st Round: ~46%, Final Round: ~54%, Random: ~50%
* **Gemma Oracle:** After 1st Round: ~46%, Final Round: ~61%, Random: ~50%
* **Gemma Bayesian:** After 1st Round: ~46%, Final Round: ~73%, Random: ~50%
* **Gemma Direct FT:** After 1st Round: ~46%, Final Round: ~76%, Random: ~50%
* **Llama Original:** After 1st Round: ~50%, Final Round: ~59%, Random: ~50%
* **Llama Oracle:** After 1st Round: ~50%, Final Round: ~63%, Random: ~50%
* **Llama Bayesian:** After 1st Round: ~50%, Final Round: ~70%, Random: ~50%
* **Llama Direct FT:** After 1st Round: ~50%, Final Round: ~84%, Random: ~50%
* **Owen Original:** After 1st Round: ~42%, Final Round: ~43%, Random: ~42%
* **Owen Oracle:** After 1st Round: ~42%, Final Round: ~66%, Random: ~42%
* **Owen Bayesian:** After 1st Round: ~42%, Final Round: ~69%, Random: ~42%
* **Owen Direct FT:** After 1st Round: ~42%, Final Round: ~81%, Random: ~42%
### Key Observations
* The "Bayesian Assistant" consistently achieves the highest accuracy across all three tasks and strategies.
* The "Final Round" strategy generally yields higher accuracy than "After 1st Round" and "Random" for most models.
* The "Random" strategy consistently shows the lowest accuracy.
* The "Direct FT" models (Gemma Direct FT, Llama Direct FT, Owen Direct FT) perform exceptionally well in the "Web Shopping" task, surpassing other models.
* The error bars indicate some variability in performance, but the overall trends are clear.
### Interpretation
The data suggests that Bayesian approaches, particularly when implemented as an "Assistant", significantly improve performance in these recommendation tasks. The improvement from "After 1st Round" to "Final Round" indicates that iterative refinement of the models is beneficial. The poor performance of the "Random" strategy highlights the importance of structured learning and reasoning. The exceptional performance of the "Direct FT" models in "Web Shopping" suggests that fine-tuning on task-specific data is highly effective for that particular domain. The consistent superiority of the Bayesian Assistant across all tasks suggests a robust and generalizable approach to recommendation. The error bars suggest that while the trends are clear, there is some inherent variability in the model performance, which could be due to the randomness in the data or the model initialization. The data demonstrates the effectiveness of different strategies and model architectures for various recommendation tasks, providing valuable insights for future model development.