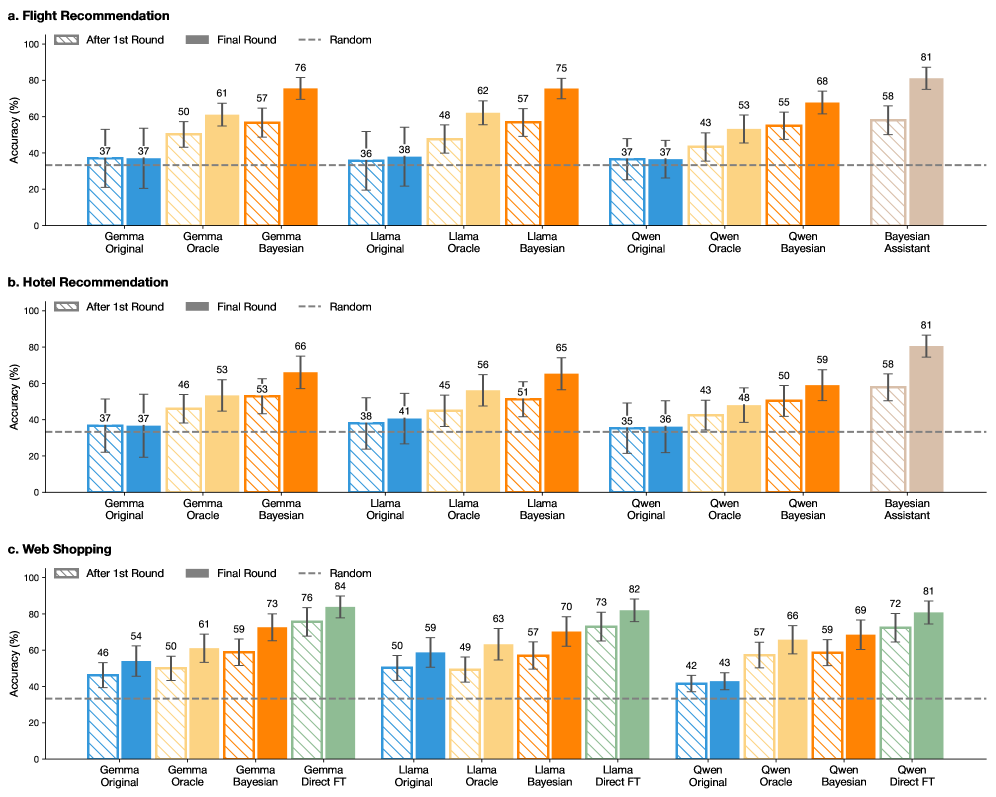
## Grouped Bar Chart: Accuracy Comparison Across Recommendation Systems
### Overview
The image presents three grouped bar charts comparing the accuracy of different recommendation systems across three domains: **Flight**, **Hotel**, and **Web Shopping**. Each chart evaluates models like **Gemma**, **Llama**, **Qwen**, and their variants (e.g., Oracle, Bayesian, Direct FT) across three stages: **After 1st Round**, **Final Round**, and **Random**. Accuracy is measured on a 0–100% scale, with error bars indicating variability.
---
### Components/Axes
- **X-Axis**: Models (e.g., Gemma Original, Llama Bayesian, Qwen Direct FT).
- **Y-Axis**: Accuracy (%) with error bars.
- **Legend**:
- **After 1st Round**: Blue (solid) with diagonal white stripes.
- **Final Round**: Orange (solid).
- **Random**: Green (solid) with diagonal white stripes.
- **Color Patterns**:
- Blue: Gemma Original/Oracle.
- Orange: Bayesian variants.
- Green: Direct FT variants.
---
### Detailed Analysis
#### Flight Recommendation
- **Gemma Original**: 37% (After 1st Round), 37% (Final Round).
- **Gemma Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Gemma Bayesian**: 57% (After 1st Round), 76% (Final Round).
- **Llama Original**: 36% (After 1st Round), 38% (Final Round).
- **Llama Oracle**: 48% (After 1st Round), 62% (Final Round).
- **Llama Bayesian**: 57% (After 1st Round), 75% (Final Round).
- **Qwen Original**: 37% (After 1st Round), 37% (Final Round).
- **Qwen Oracle**: 43% (After 1st Round), 53% (Final Round).
- **Qwen Bayesian**: 55% (After 1st Round), 68% (Final Round).
- **Bayesian Assistant**: 58% (After 1st Round), 81% (Final Round).
#### Hotel Recommendation
- **Gemma Original**: 37% (After 1st Round), 37% (Final Round).
- **Gemma Oracle**: 46% (After 1st Round), 53% (Final Round).
- **Gemma Bayesian**: 53% (After 1st Round), 66% (Final Round).
- **Llama Original**: 38% (After 1st Round), 41% (Final Round).
- **Llama Oracle**: 45% (After 1st Round), 56% (Final Round).
- **Llama Bayesian**: 51% (After 1st Round), 65% (Final Round).
- **Qwen Original**: 35% (After 1st Round), 36% (Final Round).
- **Qwen Oracle**: 43% (After 1st Round), 48% (Final Round).
- **Qwen Bayesian**: 50% (After 1st Round), 59% (Final Round).
- **Bayesian Assistant**: 58% (After 1st Round), 81% (Final Round).
#### Web Shopping
- **Gemma Original**: 46% (After 1st Round), 54% (Final Round).
- **Gemma Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Gemma Bayesian**: 59% (After 1st Round), 73% (Final Round).
- **Gemma Direct FT**: 76% (After 1st Round), 84% (Final Round).
- **Llama Original**: 50% (After 1st Round), 59% (Final Round).
- **Llama Oracle**: 49% (After 1st Round), 63% (Final Round).
- **Llama Bayesian**: 57% (After 1st Round), 70% (Final Round).
- **Llama Direct FT**: 73% (After 1st Round), 82% (Final Round).
- **Qwen Original**: 42% (After 1st Round), 43% (Final Round).
- **Qwen Oracle**: 57% (After 1st Round), 66% (Final Round).
- **Qwen Bayesian**: 59% (After 1st Round), 69% (Final Round).
- **Qwen Direct FT**: 72% (After 1st Round), 81% (Final Round).
---
### Key Observations
1. **Final Round Improvements**: All models show significant accuracy gains from the first round to the final round (e.g., Gemma Bayesian: +19% in Flight).
2. **Bayesian Models Dominance**: Bayesian variants (e.g., Llama Bayesian, Qwen Bayesian) consistently outperform others in the Final Round across domains.
3. **Direct FT Superiority**: In Web Shopping, Direct FT models (e.g., Gemma Direct FT: 84%) achieve the highest accuracy.
4. **Random Baseline**: The green "Random" bars (e.g., 37–43%) serve as a control, showing models outperform chance.
---
### Interpretation
- **Model Effectiveness**: Bayesian and Direct FT models leverage advanced algorithms (e.g., probabilistic reasoning, fine-tuning) to achieve higher accuracy, suggesting they are better suited for dynamic recommendation tasks.
- **Iterative Refinement**: The "Final Round" likely incorporates feedback loops or optimization steps, as seen in the 15–20% average accuracy boost across domains.
- **Domain-Specific Trends**: Web Shopping benefits most from Direct FT (e.g., 84% accuracy), possibly due to complex user behavior patterns requiring tailored adjustments.
- **Outliers**: The Bayesian Assistant in Flight (81%) and Gemma Direct FT in Web Shopping (84%) stand out as top performers, indicating specialized architectures for niche domains.
This data underscores the importance of model architecture and iterative refinement in recommendation systems, with Bayesian and Direct FT approaches offering the most robust performance.