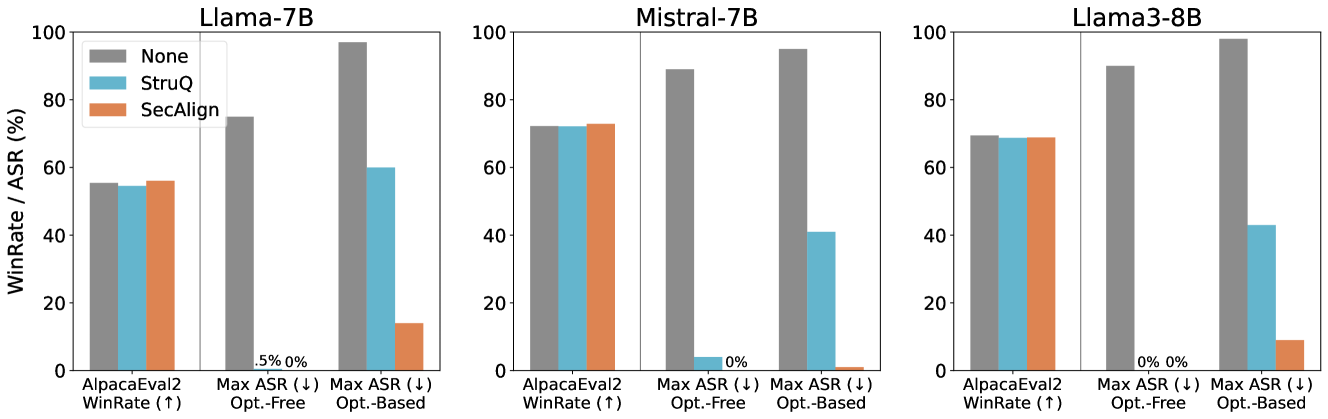
## Bar Charts: Model Performance Comparison
### Overview
The image presents three bar charts comparing the performance of different language models (Llama-7B, Mistral-7B, and Llama3-8B) under various conditions. The charts display "WinRate / ASR (%)" on the y-axis and different evaluation metrics on the x-axis. The performance is evaluated for three scenarios: "None", "StruQ", and "SecAlign".
### Components/Axes
* **Titles:**
* Left Chart: Llama-7B
* Middle Chart: Mistral-7B
* Right Chart: Llama3-8B
* **Y-Axis:**
* Label: WinRate / ASR (%)
* Scale: 0 to 100, with tick marks at 20, 40, 60, 80, and 100.
* **X-Axis:** Each chart has three categories:
* AlpacaEval2 WinRate (↑)
* Max ASR (↓) Opt.-Free
* Max ASR (↓) Opt.-Based
* **Legend:** Located at the top-left of the first chart.
* None (Gray)
* StruQ (Blue)
* SecAlign (Orange)
### Detailed Analysis
**Chart 1: Llama-7B**
* **AlpacaEval2 WinRate (↑):**
* None (Gray): ~55%
* StruQ (Blue): ~54%
* SecAlign (Orange): ~56%
* **Max ASR (↓) Opt.-Free:**
* None (Gray): ~75%
* StruQ (Blue): ~60%
* Text Annotation: ".5% 0%" - unclear association
* **Max ASR (↓) Opt.-Based:**
* None (Gray): ~100%
* StruQ (Blue): ~13%
* SecAlign (Orange): ~15%
**Chart 2: Mistral-7B**
* **AlpacaEval2 WinRate (↑):**
* None (Gray): ~72%
* StruQ (Blue): ~72%
* SecAlign (Orange): ~73%
* **Max ASR (↓) Opt.-Free:**
* None (Gray): ~88%
* StruQ (Blue): ~0%
* SecAlign (Orange): ~0%
* Text Annotation: "0%"
* **Max ASR (↓) Opt.-Based:**
* None (Gray): ~95%
* StruQ (Blue): ~0%
* SecAlign (Orange): ~0%
**Chart 3: Llama3-8B**
* **AlpacaEval2 WinRate (↑):**
* None (Gray): ~70%
* StruQ (Blue): ~69%
* SecAlign (Orange): ~69%
* **Max ASR (↓) Opt.-Free:**
* None (Gray): ~90%
* StruQ (Blue): ~0%
* SecAlign (Orange): ~0%
* Text Annotation: "0% 0%"
* **Max ASR (↓) Opt.-Based:**
* None (Gray): ~95%
* StruQ (Blue): ~43%
* SecAlign (Orange): ~9%
### Key Observations
* For AlpacaEval2 WinRate, the performance across "None", "StruQ", and "SecAlign" is relatively similar for each model.
* For Max ASR (↓) Opt.-Free and Opt.-Based, "StruQ" and "SecAlign" consistently show significantly lower ASR compared to "None" for Mistral-7B and Llama3-8B.
* Llama-7B shows a different trend for Max ASR (↓) Opt.-Free and Opt.-Based, with "StruQ" and "SecAlign" having non-zero values.
### Interpretation
The charts suggest that "StruQ" and "SecAlign" methods are effective in reducing the Maximum Attack Success Rate (ASR) for Mistral-7B and Llama3-8B, especially in optimized scenarios. The AlpacaEval2 WinRate remains relatively stable across different methods, indicating that the reduction in ASR does not significantly impact the model's general performance. Llama-7B behaves differently, suggesting that the effectiveness of "StruQ" and "SecAlign" may be model-dependent. The arrows (↑) and (↓) indicate whether a higher or lower value is desirable for each metric (WinRate and ASR, respectively).