\n
## Bar Charts: Model Performance Comparison with Alignment Techniques
### Overview
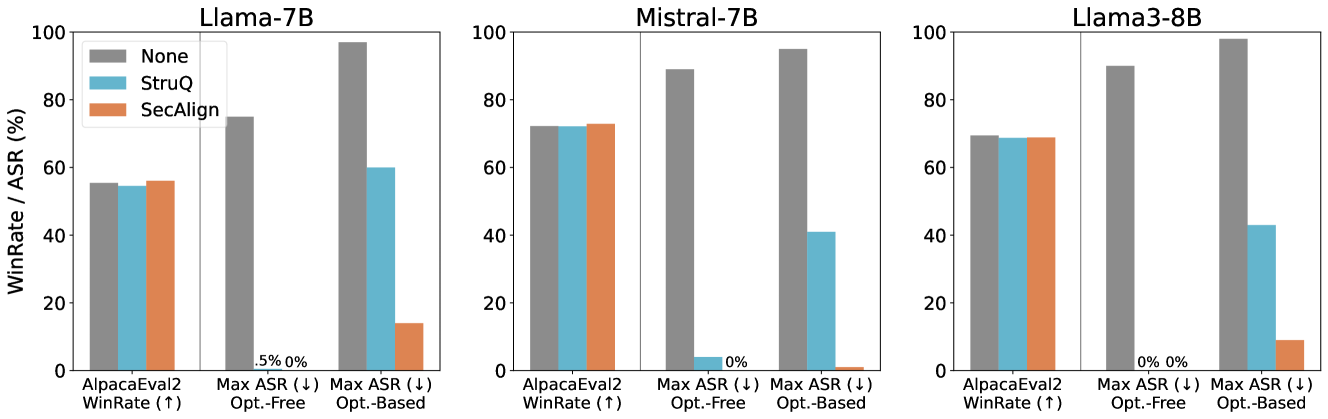
The image presents three bar charts comparing the performance of three language models – Llama-7B, Mistral-7B, and Llama3-8B – under different alignment techniques: None, StruQ, and SecAlign. The performance is measured using two metrics: WinRate and Max ASR (Automatic Speech Recognition). The charts compare performance on AlpacaEval2, Opt.-Free, and Opt.-Based datasets.
### Components/Axes
* **X-axis:** Represents the evaluation datasets and metrics: "AlpacaEval2 WinRate (↑)", "Max ASR (↓) Opt.-Free", and "Max ASR (↓) Opt.-Based". The "↑" and "↓" symbols indicate whether higher or lower values are desirable for the metric, respectively.
* **Y-axis:** Represents the WinRate / ASR (%) with a scale from 0 to 100.
* **Models:** Three separate charts are displayed, one for each model: Llama-7B, Mistral-7B, and Llama3-8B. Each chart has the same X and Y axes.
* **Legend:** Located at the top-right of each chart, the legend identifies the alignment techniques using colors:
* None (light grey)
* StruQ (light blue)
* SecAlign (dark teal)
### Detailed Analysis or Content Details
**Llama-7B Chart:**
* **AlpacaEval2 WinRate (↑):**
* None: Approximately 54%
* StruQ: Approximately 58%
* SecAlign: Approximately 62%
* **Max ASR (↓) Opt.-Free:**
* None: Approximately 5%
* StruQ: Approximately 2%
* SecAlign: Approximately 1%
* **Max ASR (↓) Opt.-Based:**
* None: Approximately 5%
* StruQ: Approximately 2%
* SecAlign: Approximately 1%
**Mistral-7B Chart:**
* **AlpacaEval2 WinRate (↑):**
* None: Approximately 72%
* StruQ: Approximately 75%
* SecAlign: Approximately 70%
* **Max ASR (↓) Opt.-Free:**
* None: Approximately 0%
* StruQ: Approximately 0%
* SecAlign: Approximately 0%
* **Max ASR (↓) Opt.-Based:**
* None: Approximately 0%
* StruQ: Approximately 0%
* SecAlign: Approximately 0%
**Llama3-8B Chart:**
* **AlpacaEval2 WinRate (↑):**
* None: Approximately 65%
* StruQ: Approximately 68%
* SecAlign: Approximately 70%
* **Max ASR (↓) Opt.-Free:**
* None: Approximately 0%
* StruQ: Approximately 0%
* SecAlign: Approximately 0%
* **Max ASR (↓) Opt.-Based:**
* None: Approximately 0%
* StruQ: Approximately 0%
* SecAlign: Approximately 0%
### Key Observations
* **WinRate:** Across all models, applying StruQ and SecAlign generally improves WinRate on the AlpacaEval2 dataset. SecAlign consistently shows the highest WinRate.
* **Max ASR:** The Max ASR scores are generally low across all models and alignment techniques, especially on the Opt.-Free and Opt.-Based datasets. StruQ and SecAlign consistently achieve lower Max ASR scores than None.
* **Model Differences:** Mistral-7B demonstrates the highest baseline WinRate (without alignment) compared to Llama-7B and Llama3-8B.
* **Alignment Impact:** The impact of alignment techniques (StruQ and SecAlign) is more pronounced for Llama-7B, showing a larger improvement in both WinRate and Max ASR.
### Interpretation
The data suggests that alignment techniques, particularly SecAlign, can improve the performance of language models, as measured by WinRate on the AlpacaEval2 dataset. The reduction in Max ASR scores indicates that alignment also helps to reduce errors in speech recognition tasks. The differences in performance between the models suggest that the underlying architecture and training data of each model influence its susceptibility to improvement through alignment.
The consistent low Max ASR scores for Mistral-7B and Llama3-8B, even without alignment, suggest these models already perform well on speech recognition tasks. The larger gains observed with Llama-7B indicate that alignment is particularly beneficial for models that initially struggle with these tasks.
The use of "↑" and "↓" symbols on the x-axis is crucial for interpreting the results. Higher WinRate is desirable, while lower Max ASR is desirable. This allows for a clear understanding of whether the alignment techniques are improving or degrading performance on each metric. The data provides insights into the effectiveness of different alignment strategies for enhancing the capabilities of language models in various applications.