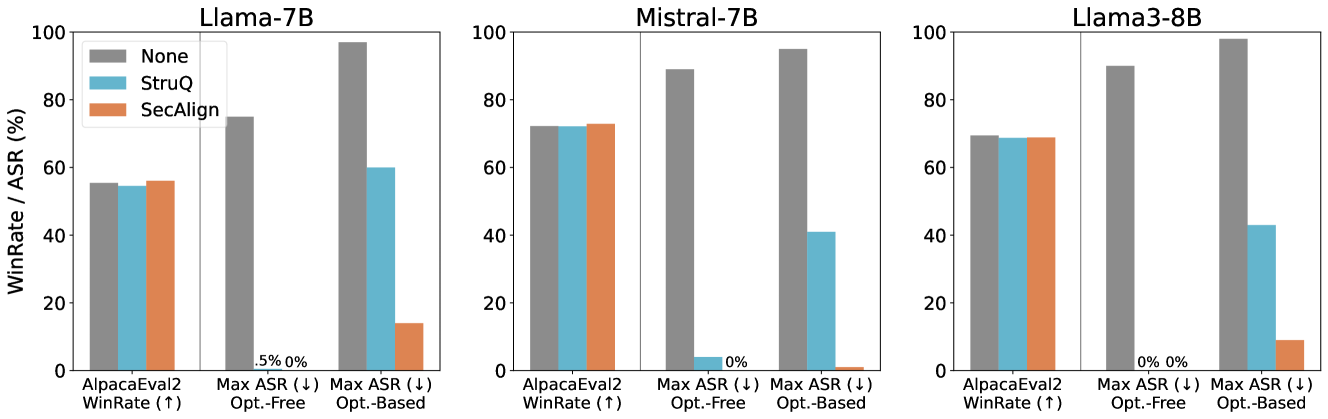
## Bar Chart: Model Performance Comparison (Llama-7B, Mistral-7B, Llama3-8B)
### Overview
The chart compares three AI models (Llama-7B, Mistral-7B, Llama3-8B) across three evaluation metrics: **AlpacaEval2 WinRate**, **Max ASR (Opt.-Free)**, and **Max ASR (Opt.-Based)**. Performance is measured using three methods: **None**, **StruQ**, and **SecAlign**, represented by distinct colors (gray, blue, orange). The y-axis shows percentages (%).
### Components/Axes
- **X-Axis**:
- Categories:
1. AlpacaEval2 WinRate (↑)
2. Max ASR (↓) Opt.-Free
3. Max ASR (↓) Opt.-Based
- **Y-Axis**: WinRate / ASR (%) (0–100 scale)
- **Legend**:
- Top-left corner, labeled:
- **None** (gray)
- **StruQ** (blue)
- **SecAlign** (orange)
- **Model Sections**:
- Llama-7B (leftmost group)
- Mistral-7B (middle group)
- Llama3-8B (rightmost group)
### Detailed Analysis
#### Llama-7B
- **AlpacaEval2 WinRate**:
- None: ~55%
- StruQ: ~54%
- SecAlign: ~57%
- **Max ASR (Opt.-Free)**:
- None: ~98%
- StruQ: ~0.5%
- SecAlign: ~0%
- **Max ASR (Opt.-Based)**:
- None: ~98%
- StruQ: ~60%
- SecAlign: ~15%
#### Mistral-7B
- **AlpacaEval2 WinRate**:
- None: ~72%
- StruQ: ~73%
- SecAlign: ~74%
- **Max ASR (Opt.-Free)**:
- None: ~90%
- StruQ: ~5%
- SecAlign: ~0%
- **Max ASR (Opt.-Based)**:
- None: ~95%
- StruQ: ~40%
- SecAlign: ~1%
#### Llama3-8B
- **AlpacaEval2 WinRate**:
- None: ~70%
- StruQ: ~70%
- SecAlign: ~70%
- **Max ASR (Opt.-Free)**:
- None: ~92%
- StruQ: ~0%
- SecAlign: ~0%
- **Max ASR (Opt.-Based)**:
- None: ~98%
- StruQ: ~43%
- SecAlign: ~8%
### Key Observations
1. **AlpacaEval2 WinRate**:
- SecAlign slightly outperforms None and StruQ in all models.
- Mistral-7B shows the highest performance (~74%).
2. **Max ASR (Opt.-Free)**:
- "None" dominates with near-perfect scores (90–98%).
- StruQ and SecAlign collapse to near-zero effectiveness.
3. **Max ASR (Opt.-Based)**:
- "None" maintains high performance (92–98%).
- StruQ and SecAlign show significant drops (1–60%), with SecAlign performing worst.
### Interpretation
- **Trade-offs in Methods**:
- "None" consistently excels in **Max ASR (Opt.-Free)**, suggesting baseline models perform well without optimization.
- **SecAlign** improves **AlpacaEval2 WinRate** but underperforms in **Max ASR (Opt.-Based)**, indicating potential overfitting or misalignment in optimization.
- **StruQ** shows mixed results: near-zero in **Max ASR (Opt.-Free)** but moderate gains in **Max ASR (Opt.-Based)** for Llama-7B.
- **Model-Specific Behavior**:
- Llama-7B and Mistral-7B show similar trends, while Llama3-8B’s **Max ASR (Opt.-Based)** for SecAlign (~8%) is anomalously low, warranting further investigation.
- **Implications**:
- Optimization methods (StruQ, SecAlign) may introduce instability in **Max ASR (Opt.-Based)**, reducing reliability.
- AlpacaEval2 WinRate improvements with SecAlign suggest better alignment with evaluation criteria but at the cost of generalization in optimization scenarios.