\n
## Diagram: Four-Step RAG-Enhanced LLM Interaction Flow
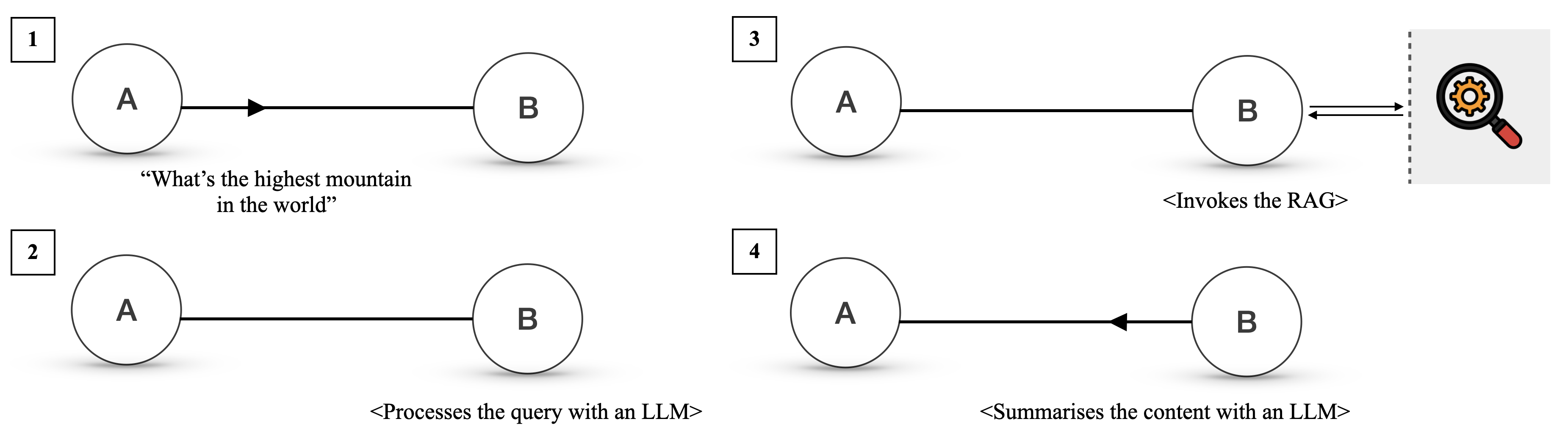
### Overview
The image is a technical diagram illustrating a four-step process for handling a user query using a Large Language Model (LLM) augmented with a Retrieval-Augmented Generation (RAG) system. The diagram is divided into four numbered quadrants (1-4), each depicting a stage in the interaction between two primary entities, labeled "A" and "B". The flow demonstrates how a factual query is processed, enriched with external data, and summarized.
### Components/Elements
* **Primary Entities:** Two circles labeled **A** and **B** appear in each step. Based on the context, "A" likely represents the **User/Client**, and "B" represents the **AI System/LLM Service**.
* **Communication Flow:** Arrows between A and B indicate the direction of information transfer.
* **Numbered Steps:** Each stage is marked with a number (1, 2, 3, 4) inside a square box in the top-left corner of its quadrant.
* **Descriptive Text:** Each step includes a text label describing the action occurring.
* **External System Icon (Step 3):** A magnifying glass with a gear inside, set against a light gray background and separated from the main diagram by a vertical dashed line. This icon represents the **RAG (Retrieval-Augmented Generation) system** or an external knowledge base.
### Detailed Analysis
The process unfolds sequentially from step 1 to step 4:
**Step 1 (Top-Left Quadrant):**
* **Visual:** An arrow points from circle A to circle B.
* **Text:** `"What's the highest mountain in the world"`
* **Action:** Entity A (User) sends a direct factual query to Entity B (AI System).
**Step 2 (Bottom-Left Quadrant):**
* **Visual:** A solid line connects A and B, with no arrowhead, indicating an ongoing connection or processing state.
* **Text:** `<Processes the query with an LLM>`
* **Action:** Entity B (AI System) begins processing the received query using its internal Large Language Model.
**Step 3 (Top-Right Quadrant):**
* **Visual:** A solid line connects A and B. To the right of B, a double-headed arrow (`<-->`) crosses a vertical dashed line to connect with the RAG system icon.
* **Text:** `<Invokes the RAG>`
* **Action:** Entity B (AI System) determines that external information is needed and invokes the RAG system. The double-headed arrow signifies a bidirectional data retrieval request and response.
**Step 4 (Bottom-Right Quadrant):**
* **Visual:** An arrow points from circle B back to circle A.
* **Text:** `<Summarises the content with an LLM>`
* **Action:** Entity B (AI System), having received information from the RAG system, uses its LLM to synthesize and summarize the retrieved content into a final answer, which is then sent back to Entity A (User).
### Key Observations
1. **Sequential Dependency:** The steps are strictly ordered. Step 3 (RAG invocation) is contingent on the processing in Step 2, and the final summary in Step 4 depends on the data retrieved in Step 3.
2. **Role of RAG:** The RAG system is depicted as an external component, separate from the core A-B interaction. Its invocation is a critical intermediate step for answering factual queries that require up-to-date or specialized knowledge not contained within the LLM's base training data.
3. **LLM's Dual Role:** The LLM (within Entity B) is used twice: first to process and understand the initial query (Step 2), and later to synthesize the retrieved information into a coherent response (Step 4).
### Interpretation
This diagram provides a clear, high-level schematic of a **Retrieval-Augmented Generation (RAG) pipeline**. It visually explains the core value proposition of RAG: enhancing an LLM's capabilities by dynamically fetching relevant information from an external source before generating a response.
* **The Problem:** A standard LLM (Step 2) might have outdated or incomplete knowledge to answer "What's the highest mountain in the world?" accurately, especially if recent geological data or specific definitions are involved.
* **The Solution:** The system bypasses this limitation by **grounding** its response in retrieved facts. Step 3 shows the system actively seeking authoritative data. Step 4 shows the LLM not just reciting raw data, but **summarizing** it, which implies generating a natural, user-friendly answer based on the retrieved evidence.
* **Significance:** This pattern is fundamental to building reliable, factual, and up-to-date AI assistants. It reduces hallucinations (making up facts) by anchoring responses in verifiable external data. The diagram effectively communicates this workflow to a technical audience, highlighting the interaction between the user, the core AI model, and the supporting knowledge retrieval system.