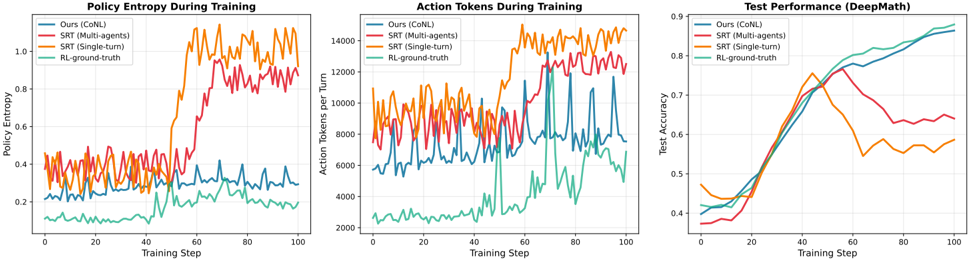
## Line Graphs: Training Metrics Comparison
### Overview
The image contains three line graphs comparing training metrics across four methods: CoNL (Ours), SRT (Multi-agents), SRT (Single-turn), and RL-ground-truth. Each graph tracks a different metric over 100 training steps: Policy Entropy, Action Tokens per Turn, and Test Accuracy (DeepMath).
---
### Components/Axes
1. **Policy Entropy During Training**
- **X-axis**: Training Step (0–100)
- **Y-axis**: Policy Entropy (0.0–1.0)
- **Legend**:
- Blue: CoNL (Ours)
- Red: SRT (Multi-agents)
- Orange: SRT (Single-turn)
- Green: RL-ground-truth
2. **Action Tokens During Training**
- **X-axis**: Training Step (0–100)
- **Y-axis**: Action Tokens per Turn (0–14,000)
- **Legend**: Same as above.
3. **Test Performance (DeepMath)**
- **X-axis**: Training Step (0–100)
- **Y-axis**: Test Accuracy (0.0–0.9)
- **Legend**: Same as above.
---
### Detailed Analysis
#### Policy Entropy During Training
- **CoNL (Blue)**: Starts at ~0.25, fluctuates between 0.2–0.4, stabilizes near 0.35 by step 100.
- **SRT (Multi-agents) (Red)**: Peaks at ~0.9 at step 60, drops to ~0.6 by step 100.
- **SRT (Single-turn) (Orange)**: Peaks at ~0.85 at step 40, declines to ~0.6 by step 100.
- **RL-ground-truth (Green)**: Smoothly increases from ~0.1 to ~0.25.
#### Action Tokens During Training
- **CoNL (Blue)**: Ranges 5,000–10,000, peaks at ~12,000 at step 60.
- **SRT (Multi-agents) (Red)**: Peaks at ~10,000 at step 40, drops to ~6,000 by step 100.
- **SRT (Single-turn) (Orange)**: Peaks at ~13,000 at step 60, declines to ~8,000 by step 100.
- **RL-ground-truth (Green)**: Stable at ~3,000.
#### Test Performance (DeepMath)
- **CoNL (Blue)**: Steady rise from ~0.4 to ~0.85.
- **SRT (Multi-agents) (Red)**: Peaks at ~0.75 at step 60, drops to ~0.6 by step 100.
- **SRT (Single-turn) (Orange)**: Peaks at ~0.7 at step 40, declines to ~0.5 by step 100.
- **RL-ground-truth (Green)**: Smoothly increases from ~0.4 to ~0.88.
---
### Key Observations
1. **RL-ground-truth** consistently outperforms other methods in test accuracy and maintains lower policy entropy.
2. **SRT (Multi-agents)** shows the highest policy entropy spikes but underperforms in test accuracy after step 60.
3. **SRT (Single-turn)** has the highest action tokens but exhibits declining test performance after step 40.
4. **CoNL** demonstrates stable learning with moderate entropy and action tokens, achieving the second-highest test accuracy.
---
### Interpretation
- **RL-ground-truth** likely represents an idealized or benchmark model, showing optimal balance between entropy, action efficiency, and accuracy.
- **SRT methods** (Multi-agents/Single-turn) exhibit higher variability, suggesting potential instability in multi-agent coordination or overfitting in single-turn scenarios.
- **CoNL**'s steady improvement indicates robust training dynamics, though it lags behind RL-ground-truth in final performance.
- The divergence between action tokens and test accuracy (e.g., SRT Single-turn's high tokens but low final accuracy) implies that token volume alone does not guarantee performance.
The data highlights trade-offs between exploration (entropy), computational efficiency (tokens), and generalization (test accuracy), with RL-ground-truth emerging as the most effective approach.