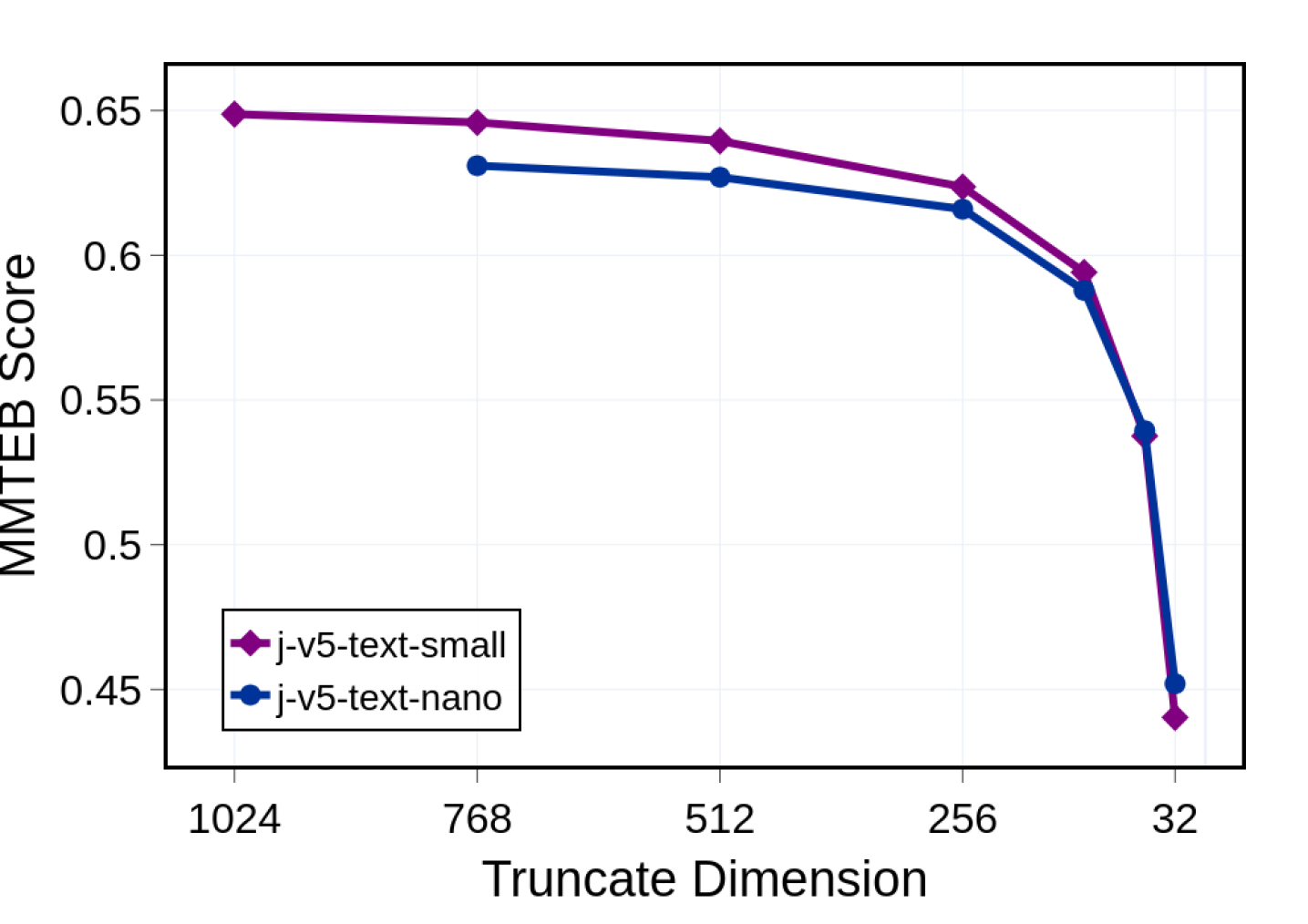
## Line Chart: MMTEB Score vs. Truncate Dimension
### Overview
The image is a line chart comparing the MMTEB (Massive Multitask Text Embedding Benchmark) scores of two models, "j-v5-text-small" and "j-v5-text-nano," across different truncate dimensions. The x-axis represents the truncate dimension, and the y-axis represents the MMTEB score.
### Components/Axes
* **X-axis:** Truncate Dimension, with values 1024, 768, 512, 256, and 32.
* **Y-axis:** MMTEB Score, ranging from 0.45 to 0.65, with increments of 0.05.
* **Legend (bottom-left):**
* Purple line with diamond markers: j-v5-text-small
* Blue line with circle markers: j-v5-text-nano
### Detailed Analysis
**1. j-v5-text-small (Purple Line, Diamond Markers):**
* **Trend:** The line generally slopes downward, indicating a decrease in MMTEB score as the truncate dimension decreases.
* **Data Points:**
* Truncate Dimension 1024: MMTEB Score ≈ 0.65
* Truncate Dimension 768: MMTEB Score ≈ 0.645
* Truncate Dimension 512: MMTEB Score ≈ 0.64
* Truncate Dimension 256: MMTEB Score ≈ 0.62
* Truncate Dimension 32: MMTEB Score ≈ 0.44
**2. j-v5-text-nano (Blue Line, Circle Markers):**
* **Trend:** The line also slopes downward, showing a decrease in MMTEB score as the truncate dimension decreases. The drop is more pronounced at lower truncate dimensions.
* **Data Points:**
* Truncate Dimension 1024: Not present
* Truncate Dimension 768: MMTEB Score ≈ 0.63
* Truncate Dimension 512: MMTEB Score ≈ 0.63
* Truncate Dimension 256: MMTEB Score ≈ 0.615
* Truncate Dimension 32: MMTEB Score ≈ 0.45
### Key Observations
* Both models exhibit a decrease in MMTEB score as the truncate dimension decreases.
* The "j-v5-text-small" model consistently outperforms the "j-v5-text-nano" model, especially at higher truncate dimensions.
* The most significant drop in performance for both models occurs between truncate dimensions 256 and 32.
### Interpretation
The chart demonstrates the impact of truncate dimension on the performance of text embedding models. As the truncate dimension decreases, the models have less context to work with, leading to a reduction in their MMTEB scores. The "j-v5-text-small" model appears to be more robust to changes in truncate dimension compared to the "j-v5-text-nano" model, maintaining a higher score across all dimensions. The sharp decline in performance at lower truncate dimensions suggests a critical threshold where the models' ability to understand and process text is significantly compromised. This information is crucial for selecting appropriate truncate dimensions for these models in real-world applications, balancing performance with computational efficiency.