# Technical Diagram Analysis: Transformer-Based Language Model Architecture
## Diagram Overview
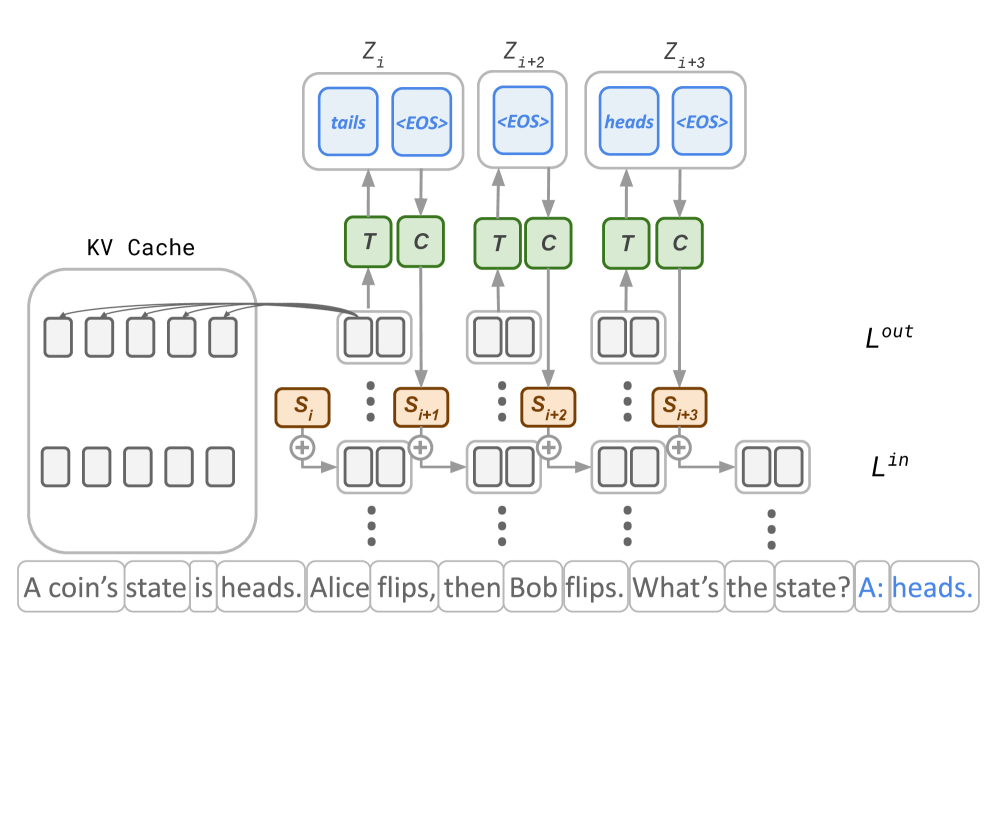
The image depicts a transformer-based language model architecture processing a natural language query. The diagram illustrates the flow of information through multiple transformer layers, attention mechanisms, and cache management components.
## Key Components and Flow
### 1. Input Processing
- **Input Tokens**:
- Sentence: "A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads."
- Tokenized as individual words in rectangular boxes at the bottom of the diagram
- **Positional Encoding**:
- Implied through sequential processing of tokens
- No explicit positional encoding markers shown
### 2. Transformer Layers
- **Layer Structure**:
- Three visible transformer layers labeled `Z_i`, `Z_i+2`, `Z_i+3`
- Each layer contains:
- **Self-Attention Mechanism**:
- Queries (`Q`), Keys (`K`), Values (`V`) processing
- Output (`O`) generation
- Attention weights (`A`) visualization
- **Feed-Forward Network**:
- Two linear layers with activation (not explicitly labeled)
- Output concatenation (`+`) operations
### 3. Cache Management
- **KV Cache**:
- Matrix structure with 10 key slots and 10 value slots
- Stores previous key-value pairs for autoregressive generation
- Connected to transformer layers via attention mechanism
### 4. Output Generation
- **Output Token**:
- Final answer: "heads" (highlighted in blue)
- Generated through autoregressive decoding process
- **Loss Functions**:
- `L_out`: Output loss (not quantified)
- `L_in`: Input loss (not quantified)
## Spatial Component Analysis
- **Legend**:
- No explicit legend present in the diagram
- Color coding used for:
- Blue: Attention mechanism components (`<EOS>`, `heads`, `tails`)
- Green: Transformer blocks (`T`, `C`)
- Orange: Positional indices (`S_i`, `S_i+1`, etc.)
- Gray: General diagram elements
## Textual Elements
### Embedded Text
- **Input Sentence**: