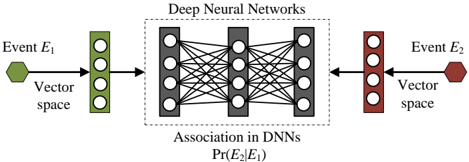
\n
## Diagram: Deep Neural Network Association Between Two Events
### Overview
The image is a technical diagram illustrating a conceptual model where a Deep Neural Network (DNN) learns an association between two distinct events, labeled Event E₁ and Event E₂. The diagram depicts a flow where each event is first mapped into a vector space, and these vector representations are then processed by a central deep neural network to model the conditional probability relationship between them.
### Components/Axes
The diagram is composed of several distinct components arranged horizontally:
1. **Left Input (Event E₁):**
* A green hexagon labeled **"Event E₁"**.
* An arrow points from this hexagon to a vertical green bar labeled **"Vector space"**. This bar contains three white circles, representing a vector or embedding.
* An arrow points from this green vector space bar into the central neural network block.
2. **Central Processing Unit (Deep Neural Network):**
* A large, dashed-outline rectangle labeled **"Deep Neural Networks"** at the top.
* Inside this rectangle is a schematic of a neural network with three layers:
* An input layer (leftmost) with 4 nodes (white circles).
* A hidden layer (middle) with 5 nodes.
* An output layer (rightmost) with 4 nodes.
* All nodes between consecutive layers are fully connected by lines, indicating a dense or fully connected network architecture.
* Below the network schematic, the text **"Association in DNNs"** is written.
* Beneath that, the mathematical notation **"Pr(E₂|E₁)"** is displayed, representing the conditional probability of Event E₂ given Event E₁.
3. **Right Input/Output (Event E₂):**
* A red hexagon labeled **"Event E₂"**.
* An arrow points from this hexagon to a vertical red bar labeled **"Vector space"**. This bar also contains three white circles.
* An arrow points from this red vector space bar *into* the central neural network block (from the right side).
### Detailed Analysis
* **Flow Direction:** The arrows indicate a bidirectional flow of information into the central DNN. The vector representation of Event E₁ flows from left to right into the network. Simultaneously, the vector representation of Event E₂ flows from right to left into the same network. This suggests the network is processing both event representations concurrently to establish their association.
* **Color Coding:** A clear color scheme is used for differentiation:
* **Green:** Associated exclusively with Event E₁ and its vector space.
* **Red:** Associated exclusively with Event E₂ and its vector space.
* **Black/Grey:** Used for the central neural network structure and all connecting arrows and text.
* **Spatial Grounding:** The legend/labels are integrated directly next to their corresponding components. "Event E₁" is top-left of its hexagon. "Vector space" labels are placed vertically alongside their respective bars. The main title "Deep Neural Networks" is centered above the network block. The explanatory text "Association in DNNs" and "Pr(E₂|E₁)" are centered below the network block.
* **Network Structure:** The DNN is depicted as a multi-layer perceptron (MLP) with a 4-5-4 node architecture across its three visible layers. The dense connections imply a complex, non-linear transformation is applied to the input vectors.
### Key Observations
1. **Symmetry in Representation:** Both events are processed through an identical conceptual pipeline (Event → Vector Space → DNN), despite being distinct (different colors, labels).
2. **Core Objective:** The explicit goal of the system, stated below the network, is to model **"Pr(E₂|E₁)"**. This frames the entire architecture as a conditional probability estimator.
3. **Abstraction Level:** The diagram is highly abstract. It does not specify the nature of the events (E₁, E₂), the dimensionality of the vector spaces, or the specific tasks (e.g., prediction, translation, causal inference) for which this association is used.
### Interpretation
This diagram conceptually represents a fundamental machine learning paradigm: using deep neural networks to learn complex, non-linear relationships between two variables or events.
* **What it demonstrates:** It shows a method where raw events are first embedded into a latent vector space (a common practice in representation learning). These embeddings are then fed into a DNN, which acts as a universal function approximator to learn the mapping or statistical dependency between them. The output is not a single prediction but the learned model of the conditional probability distribution.
* **How elements relate:** The vector spaces serve as an intermediate, structured representation that the neural network can efficiently process. The DNN is the core engine that discovers patterns and correlations within these joint representations to quantify how the occurrence of E₁ informs the likelihood of E₂.
* **Notable Implications:** The bidirectional arrows into the DNN are particularly interesting. They could imply that the network is trained on pairs of (E₁, E₂) data, or that it performs an operation like computing a joint energy or similarity score between the two event embeddings. The notation **Pr(E₂|E₁)** strongly suggests a predictive or causal modeling context, where the system is designed to answer "Given that E₁ has happened, what is the probability that E₂ will happen?" based on learned historical associations. This framework is applicable to numerous domains, from natural language processing (e.g., word2vec, translation) to time-series forecasting and causal discovery.