## Bar Charts: Sound Localization and Matching Performance
### Overview
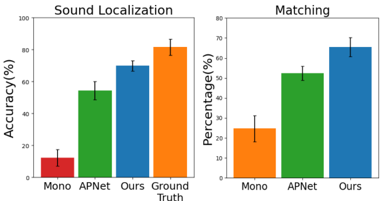
The image contains two side-by-side bar charts comparing the performance of three methods ("Mono," "APNet," "Ours") against a "Ground Truth" benchmark in two tasks: **Sound Localization** (left) and **Matching** (right). The charts use color-coded bars to represent accuracy percentages, with error bars indicating variability.
---
### Components/Axes
#### Left Chart: Sound Localization
- **X-axis**: Categories labeled "Mono," "APNet," "Ours," and "Ground Truth."
- **Y-axis**: Accuracy (%) ranging from 0% to 100%.
- **Legend**:
- Red: Mono
- Green: APNet
- Blue: Ours
- Orange: Ground Truth
- **Error Bars**: Small horizontal lines atop each bar, indicating measurement uncertainty (exact values not specified).
#### Right Chart: Matching
- **X-axis**: Categories labeled "Mono," "APNet," and "Ours."
- **Y-axis**: Percentage (%) ranging from 0% to 80%.
- **Legend**:
- Orange: Mono
- Green: APNet
- Blue: Ours
- **Error Bars**: Similar to the left chart, with small horizontal lines.
---
### Detailed Analysis
#### Sound Localization
- **Mono**: ~10% accuracy (red bar, shortest).
- **APNet**: ~55% accuracy (green bar, second shortest).
- **Ours**: ~70% accuracy (blue bar, second tallest).
- **Ground Truth**: ~80% accuracy (orange bar, tallest).
#### Matching
- **Mono**: ~25% performance (orange bar, shortest).
- **APNet**: ~50% performance (green bar, middle height).
- **Ours**: ~65% performance (blue bar, tallest).
---
### Key Observations
1. **Sound Localization**:
- "Ours" outperforms "Mono" and "APNet" by significant margins.
- "Ground Truth" (80%) serves as the upper performance limit, with "Ours" (70%) approaching it closely.
2. **Matching**:
- "Ours" achieves the highest performance (65%), doubling "Mono" (25%) and surpassing "APNet" (50%).
- No "Ground Truth" category is included, suggesting the comparison is limited to the three methods.
---
### Interpretation
- **Performance Trends**: Both charts show a clear upward trend in performance from "Mono" to "Ours," indicating that the proposed method ("Ours") improves upon baseline approaches. In Sound Localization, "Ours" nears the "Ground Truth," suggesting near-optimal performance. In Matching, "Ours" dominates without a direct benchmark, implying strong relative efficacy.
- **Method Comparison**: "APNet" consistently underperforms relative to "Ours" in both tasks, while "Mono" (likely a monaural baseline) lags significantly.
- **Ground Truth Role**: The inclusion of "Ground Truth" in the Sound Localization chart provides a critical reference point, highlighting how close "Ours" comes to human-level or ideal performance. Its absence in the Matching chart limits direct comparison to an ideal.
- **Error Bars**: The small error bars across all categories suggest low variability in measurements, reinforcing the reliability of the reported values.
---
### Conclusion
The data demonstrates that the "Ours" method significantly outperforms existing approaches ("Mono," "APNet") in both Sound Localization and Matching tasks. Its performance in Sound Localization is particularly notable, achieving 70% accuracy—close to the "Ground Truth" of 80%. This suggests the method is highly effective and potentially state-of-the-art for these tasks. The absence of a "Ground Truth" in the Matching chart leaves room for further validation against an ideal benchmark.