TECHNICAL ASSET FINGERPRINT
10a89a348cbfede949bc6f01
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
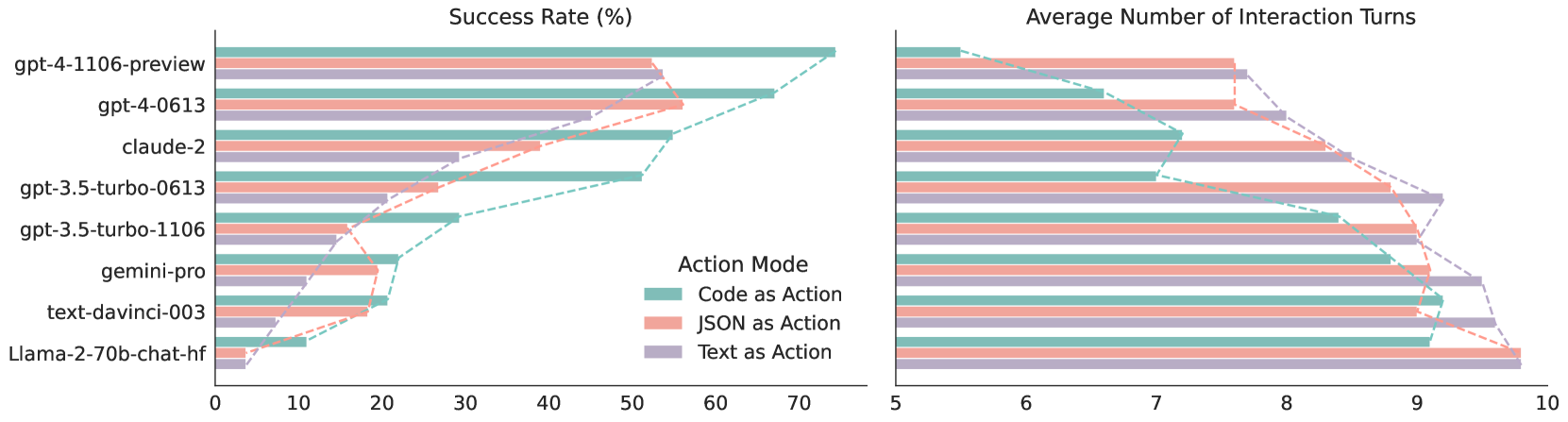
## Comparative Line Chart: Model Performance in Action Mode
### Overview
This image presents a comparative line chart displaying the performance of several large language models (LLMs) across two metrics: Success Rate (%) and Average Number of Interaction Turns. The models are evaluated under three different "Action Modes": Code as Action, JSON as Action, and Text as Action. The chart consists of two sub-charts, positioned side-by-side, one for each metric.
### Components/Axes
* **Y-axis (Left Chart):** Success Rate (%), ranging from 0 to 70.
* **Y-axis (Right Chart):** Average Number of Interaction Turns, ranging from 5 to 10.
* **X-axis (Both Charts):** Models listed vertically:
* gpt-4-1106-preview
* gpt-4-0613
* claude-2
* gpt-3.5-turbo-0613
* gpt-3.5-turbo-1106
* gemini-pro
* text-davinci-003
* Llama-2-70b-chat-hf
* **Legend (Bottom-Right):**
* Code as Action (Brown)
* JSON as Action (Pink/Red)
* Text as Action (Teal/Blue)
### Detailed Analysis or Content Details
**Left Chart: Success Rate (%)**
* **gpt-4-1106-preview:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 65%.
* JSON as Action: Starts at approximately 10%, increases rapidly to approximately 70%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 60%.
* **gpt-4-0613:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 55%.
* JSON as Action: Starts at approximately 10%, increases rapidly to approximately 60%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 50%.
* **claude-2:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 45%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 50%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 40%.
* **gpt-3.5-turbo-0613:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 40%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 45%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 35%.
* **gpt-3.5-turbo-1106:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 35%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 40%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 30%.
* **gemini-pro:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 30%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 35%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 25%.
* **text-davinci-003:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 25%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 30%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 20%.
* **Llama-2-70b-chat-hf:**
* Code as Action: Starts at approximately 10%, increases steadily to approximately 20%.
* JSON as Action: Starts at approximately 10%, increases steadily to approximately 25%.
* Text as Action: Starts at approximately 20%, increases steadily to approximately 15%.
**Right Chart: Average Number of Interaction Turns**
* **gpt-4-1106-preview:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **gpt-4-0613:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **claude-2:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **gpt-3.5-turbo-0613:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **gpt-3.5-turbo-1106:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **gemini-pro:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **text-davinci-003:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
* **Llama-2-70b-chat-hf:**
* Code as Action: Starts at approximately 8.5, decreases to approximately 6.
* JSON as Action: Starts at approximately 8.5, decreases to approximately 6.
* Text as Action: Starts at approximately 8.5, decreases to approximately 6.
### Key Observations
* **Success Rate:** JSON as Action consistently yields the highest success rates across all models. gpt-4-1106-preview generally exhibits the highest success rates overall. Llama-2-70b-chat-hf consistently shows the lowest success rates.
* **Interaction Turns:** All models show a decreasing trend in the average number of interaction turns as the action mode changes. There is very little difference between the action modes for each model.
* **Correlation:** There appears to be a negative correlation between success rate and interaction turns. Models with higher success rates tend to require fewer interaction turns.
### Interpretation
The data suggests that using JSON as an action mode significantly improves the success rate of LLMs. This could be due to the structured nature of JSON, which may reduce ambiguity and improve the model's ability to correctly interpret and execute actions. The consistently high performance of gpt-4-1106-preview indicates its superior capabilities in handling action-based tasks. The low performance of Llama-2-70b-chat-hf suggests it may require further optimization for action execution. The decreasing trend in interaction turns with increasing success rate implies that more accurate models are more efficient in completing tasks, requiring less back-and-forth communication. The near-identical interaction turn counts across action modes for each model suggest that the action mode itself doesn't significantly impact the number of turns, but rather the model's inherent ability to understand and execute the task.
DECODING INTELLIGENCE...