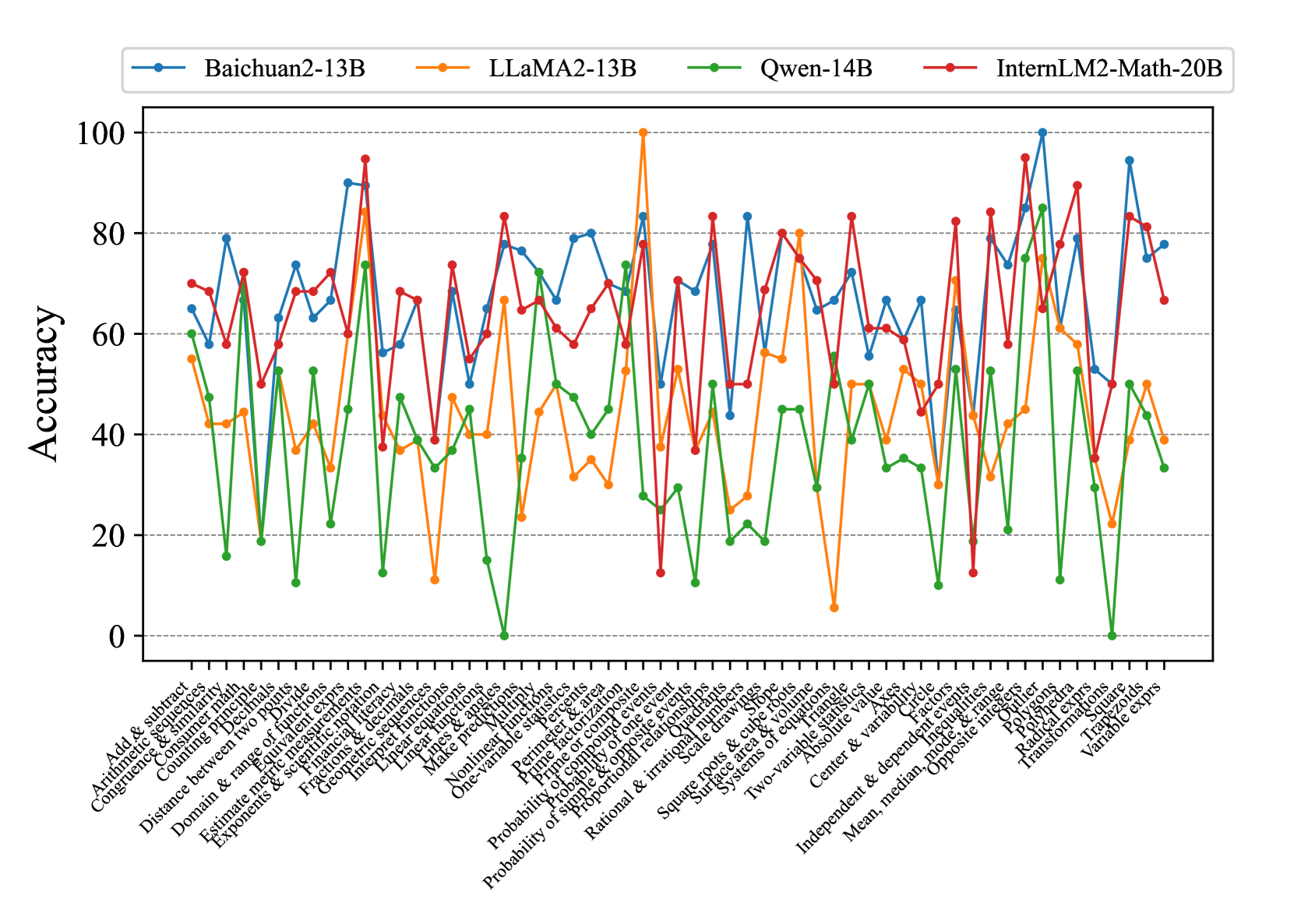
\n
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four large language models – Baichuan2-13B, LLaMA2-13B, Qwen-14B, and InternLM2-Math-20B – across a series of 31 different math problem types. The y-axis represents accuracy (ranging from 0 to 100), and the x-axis lists the math problem types. Each model's performance is represented by a distinct colored line.
### Components/Axes
* **Y-axis Title:** Accuracy
* **X-axis Title:** Math Problem Types (listed along the bottom)
* **Legend:** Located at the top-left corner, identifying each line with its corresponding model:
* Baichuan2-13B (Blue)
* LLaMA2-13B (Orange)
* Qwen-14B (Green)
* InternLM2-Math-20B (Red)
* **Math Problem Types (X-axis labels):**
1. Arithmetic & subtract
2. Complete similarity
3. Counting principles
4. Combining like terms
5. Distance between two points
6. Domain & range of functions
7. Estimates & rounding
8. Exponents & radicals
9. Fractions & percentages
10. Interpreting graphs
11. Linear equations
12. Make predictions
13. One-variable equations
14. One-variable inequalities
15. Perimeter & area
16. Probability of composite events
17. Probability of simple events
18. Proportional relationships
19. Rational & irrational numbers
20. Square roots & cube roots
21. Systems of equations
22. Two-variable equations
23. Two-variable inequalities
24. Absolute value
25. Center & variable
26. Mean, median, opposite
27. Polynomials
28. Polygon angles
29. Transform equations
30. Variable expressions
31. Volume
### Detailed Analysis
Here's a breakdown of each model's performance, noting trends and approximate accuracy values. Accuracy values are approximate due to the chart's resolution.
* **Baichuan2-13B (Blue):** The line fluctuates significantly. Starts around 60, dips to ~30, rises to ~95, then declines to ~40. Notable peaks around problem types 10, 16, and 27. Generally performs well on problems 10-17, but struggles with problems 1-9 and 28-31.
* **LLaMA2-13B (Orange):** Shows a generally increasing trend initially, peaking around 85-90 for problems 10-16. Then declines, with significant dips around problems 21, 24, and 31, falling to around 20-30. Starts around 65, peaks around 88, and ends around 30.
* **Qwen-14B (Green):** The most volatile line, with large swings in accuracy. Starts around 60, drops to near 0 for problem type 6, then rises to over 95 for problem type 10. Continues to fluctuate wildly, ending around 50. Demonstrates high accuracy on problems 10-12, but very low accuracy on problems 6, 20, and 26.
* **InternLM2-Math-20B (Red):** The most consistently high-performing model. Starts around 70, rises to a peak of approximately 98 around problem type 10, and remains relatively high (between 60 and 90) throughout the chart. Experiences a dip around problem type 26, falling to ~50, but recovers quickly.
**Specific Data Points (Approximate):**
| Problem Type | Baichuan2-13B | LLaMA2-13B | Qwen-14B | InternLM2-Math-20B |
|---|---|---|---|---|
| 1 | 60 | 65 | 60 | 70 |
| 6 | 40 | 50 | 0 | 60 |
| 10 | 95 | 88 | 98 | 98 |
| 16 | 85 | 90 | 95 | 90 |
| 21 | 50 | 25 | 60 | 75 |
| 26 | 40 | 60 | 0 | 50 |
| 31 | 30 | 30 | 50 | 70 |
### Key Observations
* InternLM2-Math-20B consistently outperforms the other models across most problem types.
* Qwen-14B exhibits the highest variability in accuracy, suggesting it may be more sensitive to the specific problem type.
* LLaMA2-13B shows a clear upward trend initially, followed by a decline, indicating it may struggle with more complex problems.
* Baichuan2-13B's performance is moderate and fluctuates considerably.
* Problem types 10-16 generally yield higher accuracy scores for all models.
* Problem types 6, 20, 26, and 31 consistently result in lower accuracy scores.
### Interpretation
The data suggests that InternLM2-Math-20B is the most robust and accurate model for solving a diverse range of math problems. The significant differences in performance across problem types highlight the challenges in developing general-purpose math solvers. The volatility observed in Qwen-14B's performance could be due to its training data or architecture, making it more prone to errors on certain types of problems. The initial success of LLaMA2-13B followed by a decline suggests a potential limitation in its ability to generalize to more complex mathematical concepts. The consistent performance of InternLM2-Math-20B likely stems from its specialized training on mathematical data. The lower accuracy on problem types 6, 20, 26, and 31 could indicate these areas require further research and development in language model-based math solving. The chart provides valuable insights into the strengths and weaknesses of each model, guiding future research efforts towards improving their mathematical reasoning capabilities.