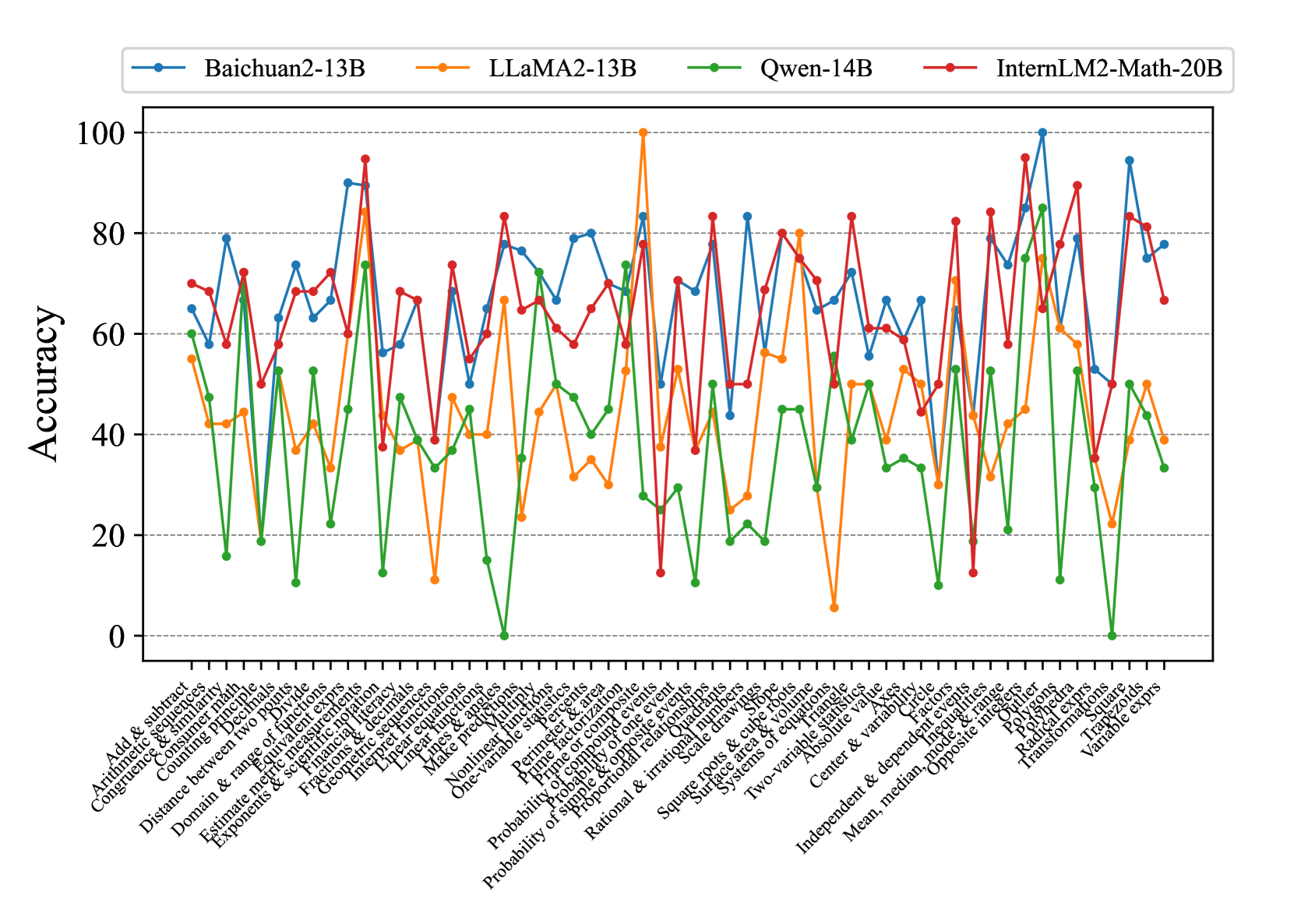
## Line Chart: Model Accuracy Across Mathematical Domains
### Overview
The chart compares the accuracy performance of four large language models (LLMs) across 30+ mathematical domains. Models include Baichuan2-13B (blue), LLaMA2-13B (orange), Qwen-14B (green), and InternLM2-Math-20B (red). Accuracy is measured on a 0-100% scale, with notable volatility in performance across different mathematical topics.
### Components/Axes
- **X-axis**: Mathematical domains (e.g., "Add & subtract," "Probability & statistics," "Polynomials")
- **Y-axis**: Accuracy percentage (0-100, increments of 20)
- **Legend**: Top-left corner with color-coded model identifiers
- **Data series**: Four distinct lines with markers (circles for Baichuan2-13B, squares for LLaMA2-13B, diamonds for Qwen-14B, and triangles for InternLM2-Math-20B)
### Detailed Analysis
1. **Baichuan2-13B (Blue)**:
- Average accuracy: ~65-75%
- Notable peaks: "Exponents & scientific notation" (~85%), "Linear equations" (~80%)
- Lowest performance: "Linear equations" (~50%)
2. **LLaMA2-13B (Orange)**:
- Highest peak: "Prime factorization" (100%)
- Sharp troughs: "Linear equations" (~10%), "Nonlinear functions" (~20%)
- Average accuracy: ~50-60%
3. **Qwen-14B (Green)**:
- Most consistent performance: ~40-50% across most domains
- Lowest point: "Linear equations" (~0%)
- Peaks: "Probability & statistics" (~60%), "Geometry" (~70%)
4. **InternLM2-Math-20B (Red)**:
- Highest overall accuracy: ~80-90% in most domains
- Peaks: "Probability & statistics" (~95%), "Polynomials" (~90%)
- Lowest performance: "Linear equations" (~60%)
### Key Observations
- **InternLM2-Math-20B** consistently outperforms others, particularly in advanced domains like "Probability & statistics" and "Polynomials."
- **Qwen-14B** shows the most significant drop in "Linear equations" (near 0% accuracy).
- **LLaMA2-13B** exhibits extreme volatility, with 100% accuracy in "Prime factorization" but near-zero in "Linear equations."
- **Baichuan2-13B** demonstrates moderate performance with fewer extreme fluctuations.
### Interpretation
The data suggests that InternLM2-Math-20B is optimized for mathematical reasoning, likely due to specialized training on mathematical datasets. Qwen-14B's poor performance in "Linear equations" may indicate a lack of focus on foundational algebraic concepts. LLaMA2-13B's volatility suggests inconsistent generalization across mathematical domains, while Baichuan2-13B shows balanced but suboptimal performance. The stark contrast in "Linear equations" accuracy across models highlights potential gaps in foundational mathematical training for some LLMs.