\n
## Line Chart: Model Accuracy on Various Tasks
### Overview
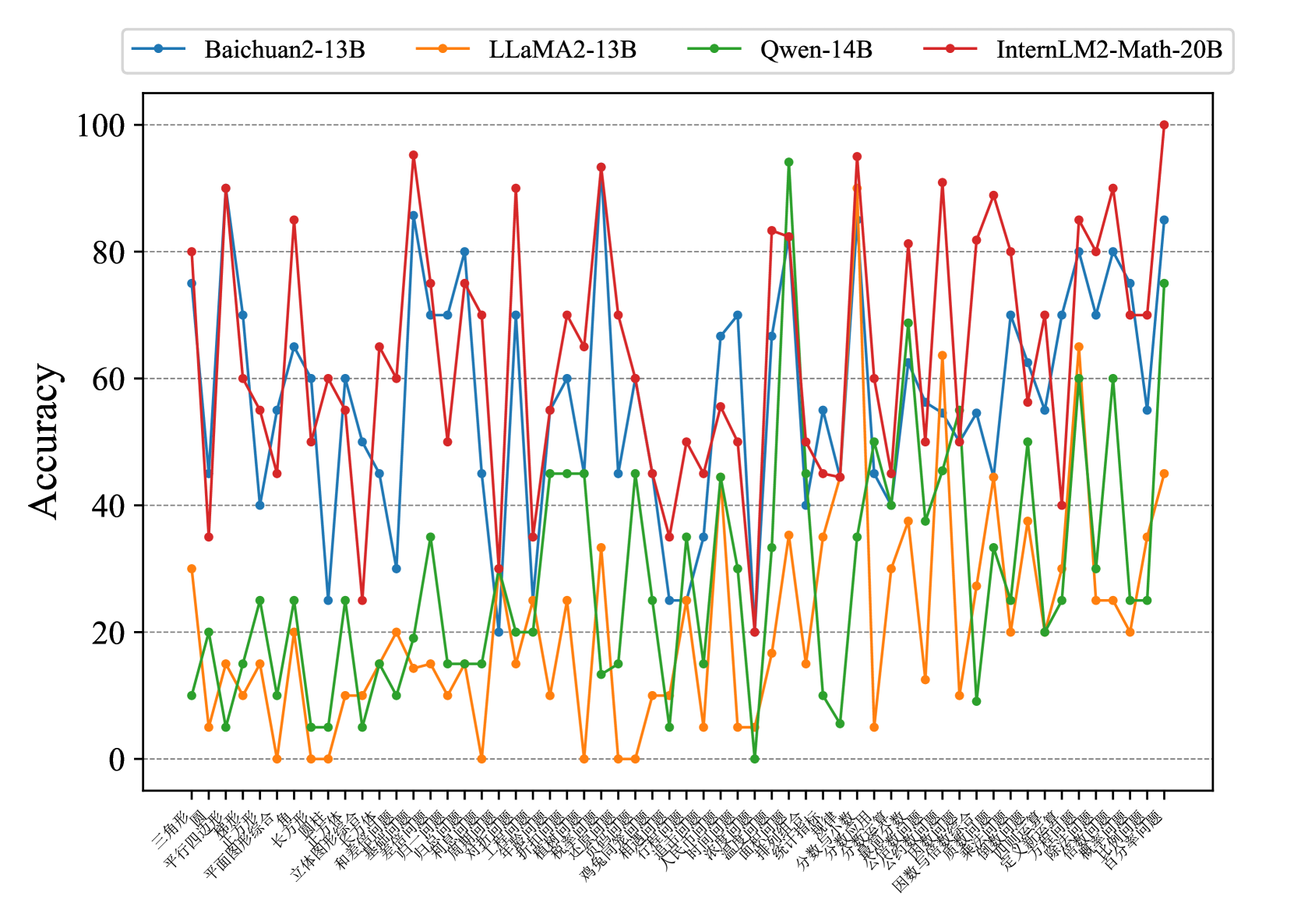
The image presents a line chart comparing the accuracy of four large language models – Baichuan2-13B, LLaMA2-13B, Qwen-14B, and InternLM2-Math-20B – across a series of tasks. The x-axis represents the tasks, labeled in Chinese characters, and the y-axis represents the accuracy, ranging from 0 to 100.
### Components/Axes
* **X-axis Title:** (Not explicitly labeled, but represents) Tasks (in Chinese)
* **Y-axis Title:** Accuracy
* **Y-axis Scale:** Linear, from 0 to 100, with increments of 20.
* **Legend:** Located at the top-center of the chart.
* **Blue Line:** Baichuan2-13B
* **Orange Line:** LLaMA2-13B
* **Green Line:** Qwen-14B
* **Red Line:** InternLM2-Math-20B
* **Tasks (X-axis Labels):** The tasks are labeled in Chinese characters. A partial translation (best effort) is provided in the Detailed Analysis section.
### Detailed Analysis
The chart displays accuracy scores for each model on each task. Due to the Chinese labels, precise task identification is difficult, but a best-effort attempt is made below. The x-axis has approximately 40 tasks.
* **Baichuan2-13B (Blue Line):** The line fluctuates significantly. It starts around 10, rises to a peak of approximately 90 around task 10, then dips and rises again, ending around 80.
* **LLaMA2-13B (Orange Line):** This line generally stays lower than the others, fluctuating between 10 and 30 for the first 20 tasks. It shows a peak around 60 at task 25, then declines to around 20-30 for the remaining tasks.
* **Qwen-14B (Green Line):** This line exhibits high variability. It starts around 15, peaks at approximately 95 around task 8, then fluctuates between 20 and 80 for the rest of the tasks.
* **InternLM2-Math-20B (Red Line):** This line shows the highest overall accuracy, with frequent peaks around 80-95. It starts around 40, rises quickly, and maintains high accuracy throughout most of the tasks, with some dips to around 60.
Here's a rough attempt at translating some of the x-axis labels (using online translation tools, accuracy not guaranteed):
* Task 1: 三种漫画 (Three Comics)
* Task 2: 平行四边形 (Parallelogram)
* Task 3: 立方体 (Cube)
* Task 4: 长方形 (Rectangle)
* Task 5: 和谐 (Harmony)
* Task 6: 立方体 (Cube)
* Task 7: 汉字 (Chinese Characters)
* Task 8: 海 (Sea)
* Task 9: 分数 (Fractions)
* Task 10: 勾股 (Pythagorean Theorem)
* Task 11: 国家 (Country)
* Task 12: 股票 (Stocks)
* Task 13: 经济 (Economy)
* Task 14: 股票 (Stocks)
* Task 15: 股票 (Stocks)
* Task 16: 股票 (Stocks)
* Task 17: 股票 (Stocks)
* Task 18: 股票 (Stocks)
* Task 19: 股票 (Stocks)
* Task 20: 股票 (Stocks)
### Key Observations
* InternLM2-Math-20B consistently outperforms the other models, particularly on tasks where high accuracy is required.
* Qwen-14B shows significant variability, with both high peaks and low troughs in accuracy.
* LLaMA2-13B generally exhibits the lowest accuracy among the four models.
* Baichuan2-13B shows a moderate level of accuracy, with fluctuations throughout the tasks.
* The tasks appear to cover a diverse range of topics, including geometry, mathematics, language, and economics.
### Interpretation
The data suggests that InternLM2-Math-20B is the most capable model across the tested tasks, likely due to its specialized training in mathematical reasoning. The high variability of Qwen-14B could indicate sensitivity to task formulation or data distribution. LLaMA2-13B's lower performance might be attributed to its smaller model size or different training data. The presence of tasks related to Chinese characters and cultural concepts (e.g., "和谐" - Harmony) suggests the models are being evaluated on their ability to handle the Chinese language and context. The repeated "股票" (Stocks) tasks suggest a focus on financial reasoning. The chart highlights the importance of model selection based on the specific task requirements and the need for further investigation into the factors influencing model performance on diverse tasks. The large fluctuations in accuracy across tasks for all models suggest that performance is highly task-dependent.