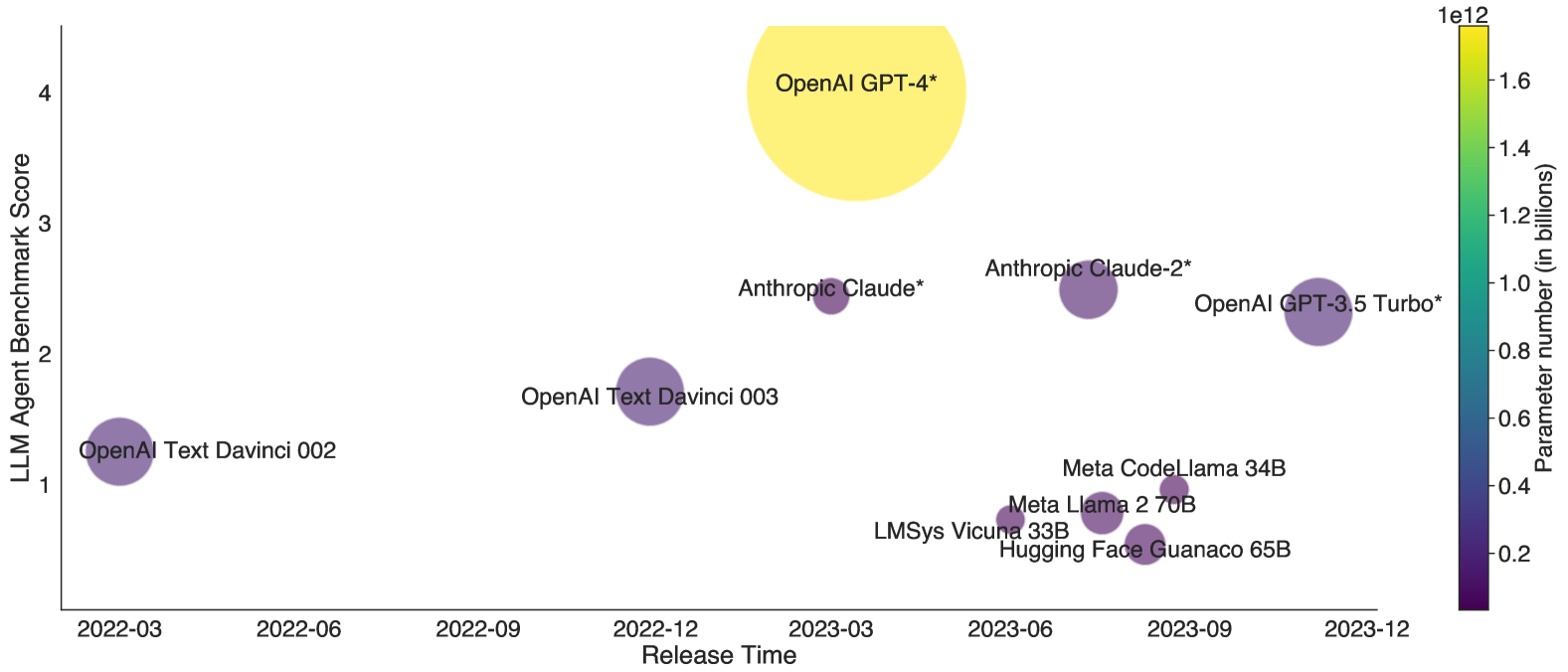
## Scatter Plot: LLM Agent Benchmark Scores vs. Release Time
### Overview
The image is a scatter plot visualizing the performance (LLM Agent Benchmark Score) of various large language models (LLMs) over time, with bubble size and color indicating parameter count. The x-axis represents release dates from March 2022 to December 2023, while the y-axis shows benchmark scores ranging from 0 to 4.0. Larger, yellower bubbles represent models with more parameters.
### Components/Axes
- **X-Axis (Release Time)**: Dates from 2022-03 to 2023-12, spaced approximately every 3 months.
- **Y-Axis (LLM Agent Benchmark Score)**: Scale from 0 to 4.0, with increments of 1.0.
- **Color Scale (Parameter Number)**: Gradient from purple (0.2B parameters) to yellow (1.6T parameters), labeled "Parameter number (in billions)".
- **Legend**: Positioned on the right, using a vertical color bar with parameter size labels (0.2B to 1.6T).
### Detailed Analysis
1. **Data Points**:
- **OpenAI GPT-4***: 1.8T parameters (yellow), score 4.0 (top-right).
- **Anthropic Claude***: 1.0T parameters (yellow-green), score 2.5 (mid-right).
- **OpenAI GPT-3.5 Turbo***: 175B parameters (green), score 2.3 (lower-right).
- **OpenAI Text Davinci 003**: 175B parameters (green), score 1.8 (mid-left).
- **Meta CodeLlama 34B**: 34B parameters (blue), score 0.9 (lower-center).
- **Meta Llama 2 70B**: 70B parameters (blue-green), score 0.8 (lower-center).
- **Hugging Face Guanaco 65B**: 65B parameters (blue-green), score 0.7 (lower-center).
- **LMSys Vicuna 33B**: 33B parameters (blue), score 0.6 (lower-center).
- **OpenAI Text Davinci 002**: 12B parameters (purple), score 1.2 (bottom-left).
2. **Trends**:
- **Parameter Size vs. Score**: Larger models (e.g., GPT-4, Claude*) generally achieve higher scores, but exceptions exist (e.g., GPT-3.5 Turbo outperforms smaller models like CodeLlama 34B).
- **Temporal Progression**: Newer models (post-2023-06) show mixed performance. GPT-4 (2023-12) dominates, while older models like Davinci 002 (2022-03) lag.
- **Color Consistency**: Bubble colors align with parameter sizes (e.g., GPT-4’s yellow matches its 1.8T parameter count, exceeding the color scale’s maximum of 1.6T).
### Key Observations
- **Outliers**: GPT-4* is the clear outlier, with the highest score and parameter count. Older models like Davinci 002 underperform despite smaller parameter counts.
- **Company Trends**: OpenAI dominates recent high-performing models, while Meta and Hugging Face models cluster in the lower score range.
- **Color Scale Limitation**: GPT-4’s parameter size (1.8T) exceeds the color scale’s maximum (1.6T), suggesting the scale may not fully represent the largest models.
### Interpretation
The data highlights a correlation between parameter count and performance, but architectural efficiency and training data quality also play critical roles. GPT-4’s exceptional score suggests breakthroughs beyond mere scale, possibly in model architecture or training techniques. The mixed performance of similarly sized models (e.g., GPT-3.5 Turbo vs. CodeLlama 34B) underscores the importance of optimization strategies. Temporal trends indicate rapid advancements, with newer models generally outperforming older ones, though exceptions persist. The color scale’s limitation for GPT-4 hints at the need for updated visualization tools to accommodate future models.