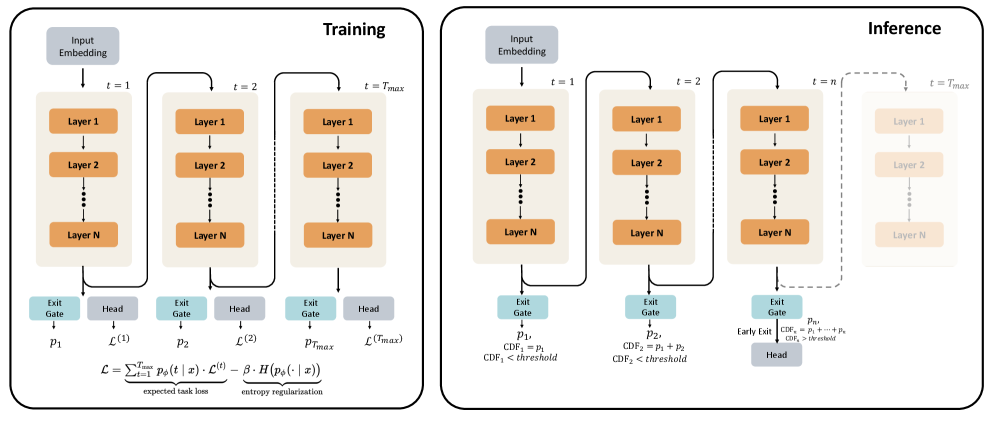
## Diagram: Training vs. Inference in a Neural Network with Early Exit
### Overview
The image presents a diagram comparing the training and inference processes in a neural network architecture that incorporates early exit mechanisms. The diagram highlights the flow of data through the network layers and the decision-making process for exiting the network early during inference.
### Components/Axes
**Left Panel: Training**
* **Title:** Training
* **Input Embedding:** A gray box at the top, representing the input to the network.
* **Layers:** Multiple blocks labeled "Layer 1", "Layer 2", ..., "Layer N" arranged vertically, representing the layers of the neural network. There are three such stacks, labeled t=1, t=2, and t=Tmax.
* **Exit Gate:** A light blue box below each layer stack, labeled "Exit Gate".
* **Head:** A gray box next to each "Exit Gate", labeled "Head".
* **Outputs:**
* `p1`, `p2`, `pTmax` below the "Exit Gate" blocks.
* `L(1)`, `L(2)`, `L(Tmax)` below the "Head" blocks.
* **Loss Function:** An equation at the bottom: `L = Σ(t=1 to Tmax) pφ(t | x) * L(t) - β * H(pφ(. | x))`. Below the equation are labels "expected task loss" and "entropy regularization".
**Right Panel: Inference**
* **Title:** Inference
* **Input Embedding:** A gray box at the top, representing the input to the network.
* **Layers:** Multiple blocks labeled "Layer 1", "Layer 2", ..., "Layer N" arranged vertically, representing the layers of the neural network. There are three such stacks, labeled t=1, t=2, and t=n. A faded stack is present, labeled t=Tmax.
* **Exit Gate:** A light blue box below the first three layer stacks, labeled "Exit Gate".
* **Head:** A gray box below the "Exit Gate" of the t=n stack, labeled "Head".
* **Outputs:**
* `p1`, `p2`, `pn` below the "Exit Gate" blocks.
* `CDF1 = p1`, `CDF1 < threshold` below `p1`.
* `CDF2 = p1 + p2`, `CDF2 < threshold` below `p2`.
* `Early Exit CDFn = p1 + ... + pn`, `CDFn > threshold` below `pn`.
**Connections:**
* Arrows indicate the flow of data between layers and components.
* A curved arrow connects the output of "Layer N" at t=1 to the input of "Layer 1" at t=2, and similarly from t=2 to t=Tmax in the Training panel, and from t=1 to t=2 to t=n in the Inference panel.
* A dashed curved arrow connects the output of "Layer N" at t=n to the input of "Layer 1" at t=Tmax in the Inference panel.
### Detailed Analysis or ### Content Details
**Training Panel:**
* The training process involves feeding input through all layers up to `Tmax`.
* At each time step `t`, an "Exit Gate" and a "Head" are present.
* The loss function `L` is calculated based on the outputs of the "Head" at each time step and includes an entropy regularization term.
**Inference Panel:**
* The inference process allows for early exits based on a threshold.
* At each time step `t`, the cumulative distribution function (CDF) is calculated.
* If the CDF exceeds a threshold, the inference process exits early.
* If the CDF does not exceed the threshold at `t=n`, the process continues to the "Head".
* The faded stack at `t=Tmax` suggests that the network can continue processing up to `Tmax` if no early exit occurs.
### Key Observations
* The key difference between training and inference is the early exit mechanism during inference.
* The training process always goes through all layers up to `Tmax`.
* The inference process can terminate early if the CDF exceeds a threshold.
### Interpretation
The diagram illustrates a neural network architecture designed for efficient inference through early exits. During training, the network learns to make predictions at each layer, and a loss function is optimized to improve the accuracy of these predictions. During inference, the network can exit early if it is confident enough in its prediction, as determined by the CDF exceeding a threshold. This early exit mechanism can significantly reduce the computational cost of inference, especially for inputs that are easy to classify. The entropy regularization term in the loss function during training likely encourages the network to make more confident predictions, which can improve the effectiveness of the early exit mechanism.