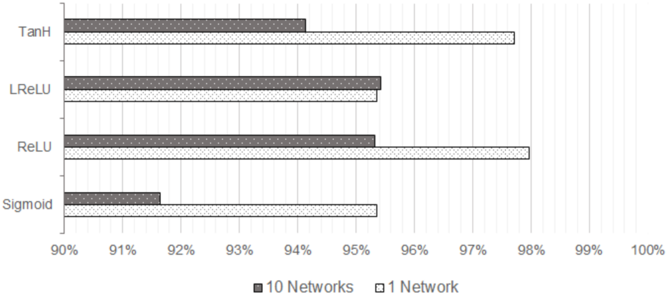
## Bar Chart: Activation Function Performance Comparison
### Overview
The chart compares the performance of four activation functions (TanH, LReLU, ReLU, Sigmoid) across two network configurations: "10 Networks" (gray bars) and "1 Network" (white bars). Performance is measured as a percentage, with values ranging from 90% to 100%.
### Components/Axes
- **Y-Axis**: Activation functions (TanH, LReLU, ReLU, Sigmoid), ordered top to bottom.
- **X-Axis**: Percentage scale from 90% to 100%, with gridlines at 1% intervals.
- **Legend**: Located at the bottom center. Gray = "10 Networks", White = "1 Network".
- **Bars**: Horizontal bars for each activation function, differentiated by color.
### Detailed Analysis
1. **TanH**:
- **10 Networks (Gray)**: Approximately 94%.
- **1 Network (White)**: Approximately 97.5%.
2. **LReLU**:
- **10 Networks (Gray)**: Approximately 95.5%.
- **1 Network (White)**: Approximately 95.5%.
3. **ReLU**:
- **10 Networks (Gray)**: Approximately 95.5%.
- **1 Network (White)**: Approximately 98%.
4. **Sigmoid**:
- **10 Networks (Gray)**: Approximately 91.5%.
- **1 Network (White)**: Approximately 95.5%.
### Key Observations
- **1 Network (White Bars)** consistently outperforms "10 Networks" (Gray Bars) across all activation functions, except LReLU, which shows near-identical performance in both configurations.
- **ReLU** achieves the highest performance in the "1 Network" configuration (98%), while **Sigmoid** has the lowest performance in the "10 Networks" configuration (91.5%).
- The largest performance gap occurs for **Sigmoid** (91.5% vs. 95.5%), suggesting it is less effective in multi-network setups.
### Interpretation
The data suggests that using a single network ("1 Network") generally yields higher performance than scaling across 10 networks. This could indicate that network complexity or resource allocation impacts activation function efficiency. Notably, **ReLU** dominates in the "1 Network" scenario, aligning with its known advantages in deep learning for mitigating vanishing gradients. The near-parity of **LReLU** in both configurations implies robustness to network scaling. Conversely, **Sigmoid**'s significant drop in the "10 Networks" setup highlights potential limitations in multi-network architectures, possibly due to its saturation behavior. These trends underscore the importance of activation function selection in optimizing network performance.