\n
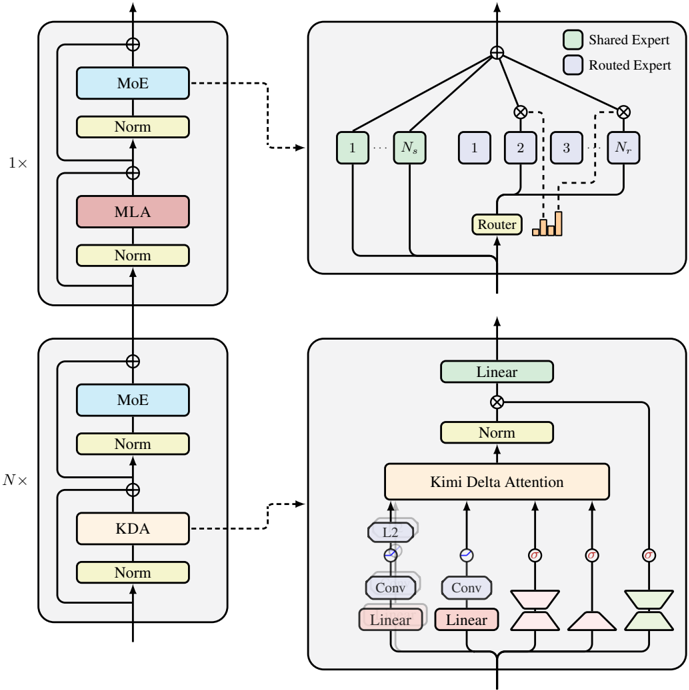
## Diagram: Mixture of Experts (MoE) Architecture
### Overview
The image depicts a diagram illustrating the architecture of a Mixture of Experts (MoE) model, likely within a larger neural network. The diagram shows two main blocks repeated N times, with a routing mechanism connecting them. The blocks contain layers labeled "MoE", "Norm", "MLA" (Multi-Layer Attention), and "KDA" (Kimi Delta Attention). The diagram also details the internal structure of the MoE layer, showing how inputs are routed to different experts.
### Components/Axes
The diagram consists of four main sections arranged in a 2x2 grid. Each section represents a component or a detailed view of a component within the MoE architecture. The key components and labels are:
* **MoE:** Mixture of Experts layer.
* **Norm:** Normalization layer.
* **MLA:** Multi-Layer Attention.
* **KDA:** Kimi Delta Attention.
* **Router:** The routing mechanism within the MoE layer.
* **Linear:** Linear transformation layer.
* **Conv:** Convolutional layer.
* **L2:** Layer labeled "L2".
* **1x:** Indicates the first block is executed once.
* **Nx:** Indicates the second block is executed N times.
* **Ns:** Indicates the number of experts.
* **Shared Expert:** Represented by a light gray box.
* **Routed Expert:** Represented by a dark gray box.
* Circles with lines connecting them: Represent connections and data flow.
* Plus signs within circles: Represent addition operations.
### Detailed Analysis or Content Details
**Top-Left Block (1x):**
This block represents the initial processing stage. It consists of:
1. A "MoE" layer (purple).
2. A "Norm" layer (yellow).
3. An "MLA" layer (red).
4. A "Norm" layer (yellow).
The output of this block is fed into the top-right block.
**Top-Right Block (MoE Detail):**
This block details the internal workings of the "MoE" layer.
1. An input is split and fed into Ns experts (labeled 1 to Ns).
2. A "Router" component directs the input to the experts.
3. The outputs of the experts are combined.
4. The legend indicates that light gray boxes represent "Shared Experts" and dark gray boxes represent "Routed Experts".
5. The outputs of the experts are multiplied with a value (represented by the circle with an 'x' inside).
**Bottom-Left Block (Nx):**
This block represents the repeated processing stage, executed N times. It consists of:
1. A "MoE" layer (purple).
2. A "Norm" layer (yellow).
3. A "KDA" layer (orange).
4. A "Norm" layer (yellow).
The output of this block is fed into the bottom-right block.
**Bottom-Right Block (KDA Detail):**
This block details the internal workings of the "KDA" layer.
1. An input is passed through two "Conv" layers (light blue).
2. Each "Conv" layer is followed by a "Linear" layer.
3. The outputs of the "Linear" layers are combined.
4. The combined output is passed through a "Kimi Delta Attention" layer (yellow).
5. The output of the "Kimi Delta Attention" layer is passed through a "Norm" layer (yellow).
6. Finally, a "Linear" layer transforms the output.
### Key Observations
* The MoE layer is a central component, appearing in both the initial and repeated processing stages.
* The diagram highlights the routing mechanism within the MoE layer, indicating that different inputs are directed to different experts.
* The KDA layer appears to be a specialized attention mechanism.
* The diagram shows a clear flow of data from left to right, with the repeated blocks suggesting an iterative process.
* The use of "Norm" layers throughout the architecture suggests a focus on stabilizing training and improving performance.
### Interpretation
The diagram illustrates a sophisticated neural network architecture leveraging the Mixture of Experts paradigm. The MoE layers allow the model to specialize in different aspects of the input data, potentially leading to increased capacity and improved performance. The routing mechanism dynamically assigns inputs to the most appropriate experts, enabling efficient learning and generalization. The KDA layer suggests a novel attention mechanism tailored to the specific needs of the model. The repeated blocks (Nx) indicate that the model processes the input data iteratively, refining its representation over multiple stages. The diagram suggests a model designed for complex tasks requiring high capacity and adaptability. The use of normalization layers throughout the architecture indicates a focus on stable training and robust performance. The diagram does not provide any quantitative data or performance metrics, but it clearly outlines the architectural principles and key components of the MoE model. The diagram is a conceptual illustration of the architecture, and does not contain any numerical data.