TECHNICAL ASSET FINGERPRINT
12b30b1ca17bc61c6afa95b3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
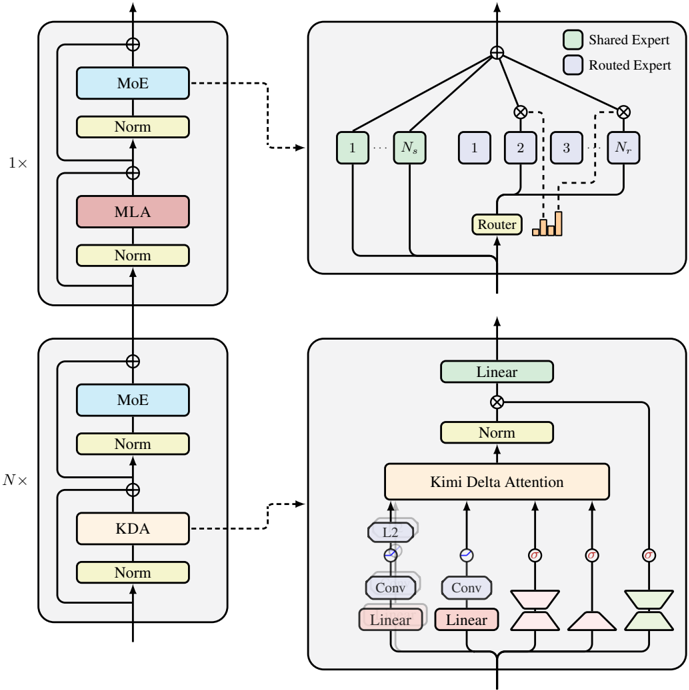
## Technical Diagram: Neural Network Architecture with Mixture of Experts (MoE) and Attention Mechanisms
### Overview
The image displays a technical architectural diagram of a neural network model, likely a transformer variant, incorporating Mixture of Experts (MoE) and specialized attention mechanisms. The diagram is structured into two main vertical sections on the left, each with a corresponding detailed expansion on the right. The overall flow is bottom-to-top, indicating data processing through stacked layers.
### Components/Axes
The diagram is a flowchart/block diagram with no numerical axes. It contains labeled blocks, directional arrows, and a legend.
**Legend (Top-Right Corner of Top Expansion):**
* **Shared Expert:** Represented by a light green box.
* **Routed Expert:** Represented by a light purple box.
**Main Structural Blocks (Left Column):**
1. **Bottom Block (Labeled "N×"):** This indicates a block that is repeated N times.
* Contains a sub-block with two main components stacked vertically:
* **KDA** (in a peach-colored box) followed by a **Norm** (normalization) layer.
* **MoE** (in a light blue box) followed by a **Norm** layer.
* A residual connection (arrow with a plus sign) bypasses the KDA and MoE sub-blocks.
2. **Top Block (Labeled "1×"):** This indicates a single, non-repeated block.
* Contains a sub-block with two main components stacked vertically:
* **MLA** (in a pink box) followed by a **Norm** layer.
* **MoE** (in a light blue box) followed by a **Norm** layer.
* A residual connection bypasses the MLA and MoE sub-blocks.
**Detailed Expansions (Right Column):**
1. **Top Expansion (Connected to "MoE" block via dashed arrow):**
* **Title/Context:** This details the internal structure of the MoE (Mixture of Experts) component.
* **Components:**
* **Shared Expert Pool:** Boxes labeled `1` through `N_s` (light green).
* **Routed Expert Pool:** Boxes labeled `1` through `N_r` (light purple).
* **Router:** A component that takes the input and outputs a routing decision (visualized as a bar chart) to select which Routed Experts to use.
* **Flow:** The input goes to all Shared Experts and the Router. The Router's output gates specific Routed Experts. The outputs from all active Shared Experts and the selected Routed Experts are combined (via a summation node, `⊕`) to produce the final output.
2. **Bottom Expansion (Connected to "KDA" block via dashed arrow):**
* **Title/Context:** This details the internal structure of the KDA (Kimi Delta Attention) component.
* **Components (from bottom to top):**
* **Input Splitting:** The input is split into multiple parallel paths.
* **Path 1 & 2:** Each consists of a **Linear** layer (pink) followed by a **Conv** (Convolution) layer (purple). Path 1 includes an additional **L2** normalization step after the Conv layer.
* **Path 3 & 4:** Each consists of a **Linear** layer (pink) followed by a distinctive trapezoidal block (likely representing a specific type of projection or transformation).
* **Kimi Delta Attention:** A central block (peach-colored) that takes the processed inputs from all four paths.
* **Post-Attention:** The output of the attention block goes through a **Norm** layer, then a **Linear** layer (light green), with a final residual connection from the original input to the output of this Linear layer.
### Detailed Analysis
* **Data Flow:** The primary data flow is upward. The input enters at the bottom of the "N×" block, passes through KDA and MoE layers (with residual connections), and this entire block is repeated N times. The output then enters the single "1×" block, passing through MLA and MoE layers before the final output at the top.
* **Component Relationships:**
* The **MoE** component is a complex sub-system that uses a combination of always-active "Shared Experts" and dynamically selected "Routed Experts" to process information, controlled by a Router.
* The **KDA** component is a specialized attention mechanism. It processes the input through four distinct parallel pathways (two with convolution, two with other projections) before fusing them in the "Kimi Delta Attention" module.
* **MLA** is another attention mechanism (likely "Multi-head Latent Attention" or similar), but its internal structure is not expanded in this diagram.
* **Spatial Grounding:**
* The **Legend** is positioned in the top-right corner of the top expansion diagram.
* The **Router** within the MoE expansion is located at the bottom-center of that sub-diagram.
* The **Kimi Delta Attention** block is centrally located within the bottom expansion diagram.
* The **"N×" and "1×" labels** are placed to the left of their respective main blocks.
### Key Observations
1. **Hybrid Architecture:** The model combines two different types of attention mechanisms (KDA and MLA) within its stack, suggesting a design aimed at capturing different types of dependencies or improving efficiency.
2. **Mixture of Experts (MoE):** The use of MoE with both shared and routed experts is a key feature for scaling model capacity without proportionally increasing computational cost for every input.
3. **Residual Connections:** Residual connections (the `⊕` symbols) are present around every major sub-block (KDA, MLA, MoE), which is standard practice for enabling deep network training.
4. **Variable Depth:** The "N×" notation indicates the core processing block is repeated, making the model depth configurable.
5. **Specialized KDA Pathways:** The KDA module's four distinct input pathways suggest it is designed to extract and transform different features from the input before applying attention.
### Interpretation
This diagram illustrates a sophisticated, large-scale neural network architecture designed for efficiency and capacity. The **core innovation appears to be the integration of two distinct attention mechanisms (KDA and MLA) with a Mixture of Experts (MoE) feed-forward network.**
* **What it suggests:** The architecture is likely designed for a task requiring both complex relational understanding (handled by the attention mechanisms) and large-scale knowledge storage/processing (handled by the MoE). The "Kimi Delta Attention" (KDA) with its multi-pathway input processing might be tailored for specific data modalities or to capture multi-scale features efficiently.
* **How elements relate:** The KDA and MLA blocks serve as the model's "reasoning" or "context-understanding" layers, while the MoE blocks act as its "knowledge" or "transformation" layers. They are stacked sequentially, with the repeated N× block forming the bulk of the model's depth, potentially for hierarchical feature extraction, and the final 1× block possibly serving as a higher-level integration stage.
* **Notable aspects:** The explicit separation of "Shared" and "Routed" experts in the MoE is a notable design choice, promoting both general and specialized processing. The absence of internal detail for the MLA block, while KDA is expanded, implies that KDA may be the novel or more critical component in this specific architecture. The overall design prioritizes modularity and scalability.
DECODING INTELLIGENCE...