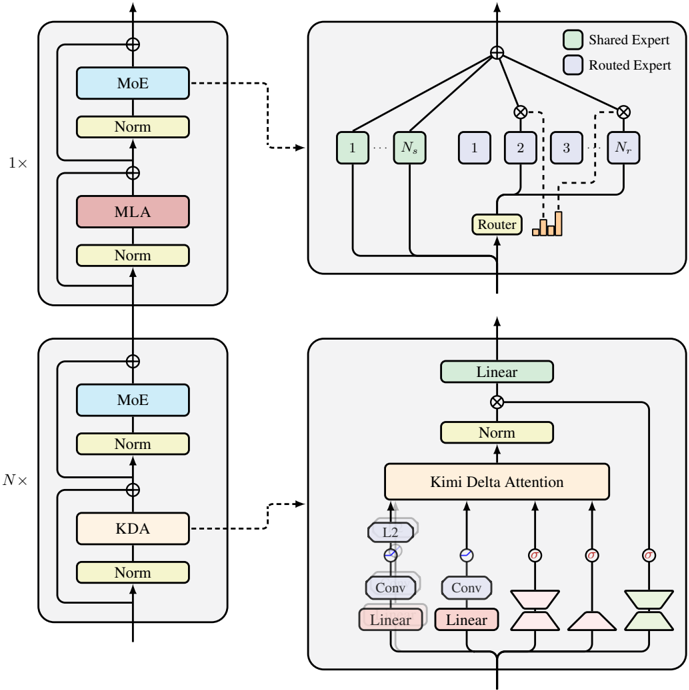
## Diagram: Neural Network Architecture with Mixture of Experts and Kimi Delta Attention
### Overview
The diagram illustrates a neural network architecture with two primary configurations: a standard Mixture of Experts (MoE) setup and an enhanced version incorporating Kimi Delta Attention. The architecture includes components like normalization layers, attention mechanisms, and routing logic, with a focus on expert selection and dynamic attention weighting.
### Components/Axes
- **Top Section (1x Configuration)**:
- **MoE (Mixture of Experts)**: A blue block labeled "MoE" with a "Norm" (Normalization) layer below it.
- **MLA (Multi-Layer Attention)**: A red block labeled "MLA" with a "Norm" layer below it.
- **Router**: A central block labeled "Router" with connections to multiple "Experts" (labeled 1 to N). The router distributes input to experts based on routing logic.
- **Shared Expert**: Green-colored blocks labeled "Shared Expert" (e.g., "1", "2", "3", "N") connected to the router.
- **Routed Expert**: Orange-colored blocks labeled "Routed Expert" (e.g., "1", "2", "3", "N") connected to the router.
- **Bottom Section (Nx Configuration)**:
- **MoE (Mixture of Experts)**: A blue block labeled "MoE" with a "Norm" layer below it.
- **KDA (Kernel Density Attention)**: A pink block labeled "KDA" with a "Norm" layer below it.
- **Linear Layer**: A green block labeled "Linear" with a "Norm" layer below it.
- **Kimi Delta Attention**: A complex block with:
- **Conv Layers**: Two "Conv" (Convolutional) layers.
- **Linear Layers**: Two "Linear" layers.
- **Attention Mechanisms**: "L2" (L2 normalization), "Conv", "Linear", and "Kimi Delta Attention" components.
- **Flow**: Input flows through MoE → KDA → Linear → Kimi Delta Attention, with connections to the router and experts.
### Detailed Analysis
- **Top Section (1x)**:
- The standard MoE setup uses a router to dynamically select experts (Shared/ Routed) based on input. The "Norm" layers ensure stable training by normalizing activations.
- The "MLA" block suggests a multi-layer attention mechanism, possibly for refining feature representations before routing.
- **Bottom Section (Nx)**:
- The enhanced configuration introduces **KDA** (Kernel Density Attention), which may optimize expert selection by analyzing input density.
- The **Kimi Delta Attention** block combines convolutional and linear layers to compute attention weights, potentially improving model adaptability.
- The "Linear" and "Norm" layers in this section likely refine the output before final processing.
### Key Observations
- **Routing Logic**: The router in the top section directs input to experts, while the bottom section’s Kimi Delta Attention may dynamically adjust routing based on input characteristics.
- **Attention Mechanisms**: Both sections use attention (MLA, Kimi Delta Attention) to focus on relevant features, but the bottom section integrates convolutional operations for spatial or temporal context.
- **Normalization**: "Norm" layers are consistently used to stabilize training across all components.
- **Color Coding**: The legend distinguishes "Shared Expert" (green) and "Routed Expert" (orange), aiding in visualizing expert selection.
### Interpretation
This diagram represents a hybrid neural network architecture combining **Mixture of Experts (MoE)** for scalability and **Kimi Delta Attention** for dynamic feature weighting. The top section emphasizes expert selection via a router, while the bottom section introduces KDA and Kimi Delta Attention to enhance adaptability. The use of convolutional layers in the Kimi Delta Attention suggests a focus on spatial or temporal relationships, potentially improving performance on complex tasks. The architecture likely balances efficiency (via MoE) and precision (via attention mechanisms), making it suitable for large-scale models requiring both scalability and contextual awareness.