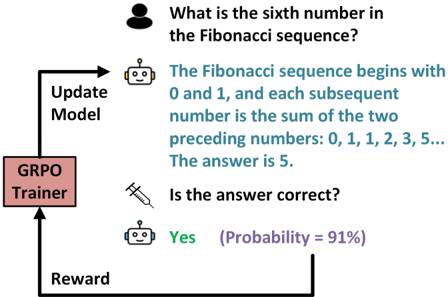
## Diagram: GRPO Trainer Feedback Loop
### Overview
The image is a conceptual diagram illustrating a reinforcement learning feedback loop, specifically focusing on the "GRPO" (Group Relative Policy Optimization) training process for an AI model. It depicts a cycle where a model is updated based on a reward signal derived from the verification of its response to a user query.
### Components/Axes
* **Central Component:** A rectangular box labeled "GRPO Trainer" located on the left side of the diagram.
* **Flow Arrows:**
* **Top Arrow:** Labeled "Update Model," pointing from the GRPO Trainer to the right, initiating the interaction.
* **Bottom Arrow:** Labeled "Reward," pointing from the right back to the GRPO Trainer, completing the feedback loop.
* **Content Blocks (Right side, top to bottom):**
* **User Query:** Represented by a person icon.
* **Model Response:** Represented by a robot icon.
* **Verification Query:** Represented by a syringe icon.
* **Verification Result:** Represented by a robot icon.
### Detailed Analysis
**1. The Interaction Flow:**
* **Initiation:** The "GRPO Trainer" (left) sends an update signal to the model.
* **User Input:** A user asks: "What is the sixth number in the Fibonacci sequence?"
* **Model Output:** The model provides a reasoning chain: "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5."
* **Verification:** A verification step (indicated by the syringe icon) asks: "Is the answer correct?"
* **Evaluation:** The result is "Yes" with a "Probability = 91%".
* **Feedback:** This result is sent back to the "GRPO Trainer" as a "Reward" signal.
**2. Textual Transcription:**
* **Left Box:** "GRPO Trainer"
* **Top Arrow Label:** "Update Model"
* **User Prompt:** "What is the sixth number in the Fibonacci sequence?"
* **Model Response:** "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5."
* **Verification Prompt:** "Is the answer correct?"
* **Verification Result:** "Yes (Probability = 91%)"
* **Bottom Arrow Label:** "Reward"
### Key Observations
* **Logical Correctness:** The model correctly identifies the Fibonacci sequence (0, 1, 1, 2, 3, 5) and correctly identifies the 6th number as 5.
* **Confidence Score:** The verification process assigns a 91% probability to the correctness of the answer, indicating a high level of confidence in the model's reasoning.
* **Iconography:** The use of a syringe icon for the verification step is unconventional in standard flowcharts; in the context of LLM training, this likely symbolizes an "evaluation" or "injection" of a ground-truth check into the training loop.
### Interpretation
This diagram represents the **Reinforcement Learning from AI Feedback (RLAIF)** or **Reinforcement Learning from Human Feedback (RLHF)** pipeline, specifically tailored for GRPO (Group Relative Policy Optimization).
* **Mechanism:** GRPO is a training method that allows models to improve by generating multiple outputs and comparing them against each other (or against a verifier) to determine which is better, rather than relying on a separate, computationally expensive "critic" model.
* **The Loop:** The diagram demonstrates the "Reward" mechanism. By verifying the model's chain-of-thought reasoning (the Fibonacci calculation) and assigning a probability score, the system creates a signal. This signal is fed back to the "GRPO Trainer" to adjust the model's policy, reinforcing correct reasoning patterns and penalizing incorrect ones.
* **Significance:** The 91% probability suggests that the verifier is highly confident in the model's output. In a training scenario, this high-confidence "Yes" would act as a positive reward, encouraging the model to continue using this specific reasoning path for similar mathematical queries in the future.