\n
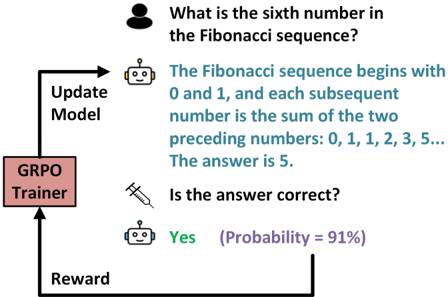
## Diagram: Reinforcement Learning Loop with GRPO Trainer
### Overview
This diagram illustrates a reinforcement learning loop involving a GRPO (Gradient-based Policy Optimization) Trainer, a model, and a user interaction. The loop demonstrates a question-answer process where the model receives feedback and updates its parameters.
### Components/Axes
The diagram consists of the following components:
* **User:** Represented by a grey head icon, posing the question.
* **Model:** Represented by a robot icon, providing the answer.
* **GRPO Trainer:** A rectangular box labeled "GRPO Trainer" in red text.
* **Arrows:** Indicate the flow of information and feedback.
* **Text Boxes:** Contain the question, answer, and feedback.
* **Syringe Icon:** Represents the question of answer correctness.
* **Probability Indicator:** "Probability = 91%" associated with the "Yes" response.
### Detailed Analysis or Content Details
The diagram depicts the following sequence:
1. **Question:** A user asks, "What is the sixth number in the Fibonacci sequence?". (Top of the image)
2. **Model Response:** The model responds with the text: "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5." (Top-right)
3. **Correctness Check:** A syringe icon asks, "Is the answer correct?". (Center)
4. **Positive Feedback:** The model responds "Yes" with a probability of 91%. (Bottom-right)
5. **Reward & Update:** A "Reward" signal is sent from the model to the "GRPO Trainer" (bottom-left). The GRPO Trainer then sends an "Update Model" signal back to the model (left side).
The arrows indicate the following flow:
* User -> Model (Question)
* Model -> User (Answer)
* Model -> GRPO Trainer (Answer & Feedback)
* GRPO Trainer -> Model (Update Model)
* Model -> GRPO Trainer (Reward)
### Key Observations
* The diagram highlights a closed-loop system where the model learns from feedback.
* The GRPO Trainer plays a central role in updating the model based on the reward signal.
* The probability of 91% suggests a high degree of confidence in the model's answer.
* The diagram does not provide any numerical data beyond the probability value.
### Interpretation
This diagram illustrates a simplified reinforcement learning process. The GRPO Trainer acts as the learning algorithm, adjusting the model's parameters based on the reward received for providing correct answers. The 91% probability indicates that the model is performing well on this particular task. The diagram demonstrates how a model can improve its performance through iterative feedback and updates. The use of a Fibonacci sequence question suggests the model is capable of mathematical reasoning. The diagram is a conceptual illustration of the process rather than a presentation of specific data or results. It focuses on the *flow* of information and the *roles* of the different components.