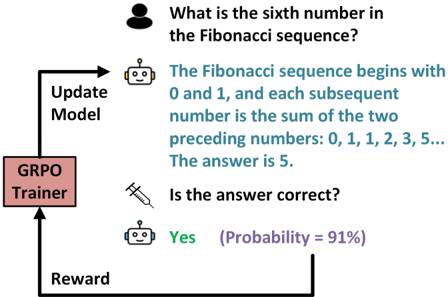
## Flowchart: GRPO Trainer Feedback Loop for Question Answering
### Overview
The image depicts a flowchart illustrating a feedback loop for a question-answering system using a GRPO (Group Relative Policy Optimization) Trainer. The process involves a human query, an AI model's response, correctness verification, and model updates based on probabilistic rewards.
### Components/Axes
1. **Human Icon**: Top-left, representing the user asking a question.
2. **Robot Icon**: Middle-left, symbolizing the AI model.
3. **Syringe Icon**: Middle-right, representing the "Update Model" action.
4. **GRPO Trainer Box**: Bottom-left, labeled "GRPO Trainer."
5. **Text Elements**:
- Question: "What is the sixth number in the Fibonacci sequence?"
- Answer: "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5."
- Correctness Check: "Is the answer correct?" with response "Yes (Probability = 91%)."
- Reward: Labeled "Reward" with an arrow looping back to the GRPO Trainer.
### Detailed Analysis
- **Question Flow**:
- The human asks about the sixth Fibonacci number.
- The robot provides the sequence definition and answers "5."
- **Correctness Verification**:
- A syringe icon (symbolizing data injection) connects the answer to a correctness check.
- The system confirms the answer is correct with 91% probability.
- **Reward Mechanism**:
- A reward signal loops back to the GRPO Trainer, which updates the model.
### Key Observations
- The Fibonacci sequence is explicitly defined in the answer, with the sixth number correctly identified as 5.
- The correctness check uses a probabilistic metric (91%), indicating confidence but not absolute certainty.
- The GRPO Trainer acts as a closed-loop system, using rewards to refine the model iteratively.
### Interpretation
This flowchart demonstrates a reinforcement learning framework where:
1. **Human Queries** trigger model responses.
2. **Probabilistic Correctness Checks** evaluate answers, balancing accuracy and uncertainty.
3. **Reward Signals** guide the GRPO Trainer to optimize the model, emphasizing iterative improvement over static training.
The 91% probability suggests the system prioritizes high-confidence updates, potentially filtering out low-certainty corrections. The syringe icon metaphorically represents the injection of feedback into the model, aligning with GRPO's focus on policy optimization through relative rewards. The loop implies continuous learning, where even "correct" answers may refine the model's understanding of edge cases or ambiguous definitions.