\n
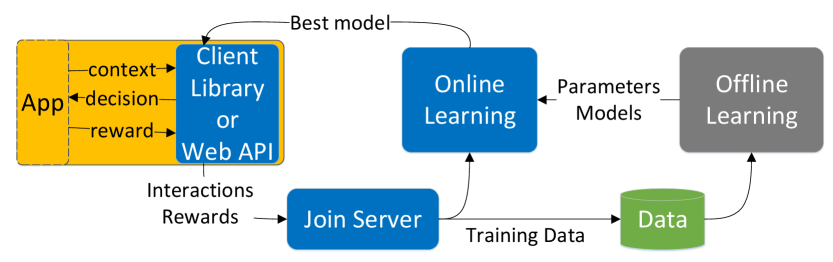
## Diagram: Reinforcement Learning System Architecture
### Overview
This diagram illustrates the architecture of a reinforcement learning system, showing the flow of data and interactions between different components. The system involves an application ("App"), a client interface (Library or Web API), online and offline learning modules, and data storage. The diagram emphasizes the iterative process of learning from interactions and rewards.
### Components/Axes
The diagram consists of the following components:
* **App (Yellow Rectangle):** Represents the application interacting with the environment.
* **Client (Blue Rectangle):** Acts as an interface between the App and the learning modules. It can be a Library or a Web API.
* **Online Learning (Blue Rectangle):** Performs real-time learning based on incoming data.
* **Offline Learning (Gray Rectangle):** Performs learning using stored data.
* **Join Server (Blue Rounded Rectangle):** Collects interactions and rewards.
* **Data (Green Cylinder):** Stores training data.
* **Parameters/Models (Text Label):** Indicates the output of the Online Learning module.
The following data flows are indicated by arrows:
* **context:** From App to Client.
* **decision:** From Client to App.
* **reward:** From App to Client.
* **Best model:** From Client to Online Learning.
* **Interactions & Rewards:** From Join Server to Client.
* **Training Data:** From Join Server to Data.
* **Parameters/Models:** From Online Learning to Offline Learning.
* Data flow from Data to Offline Learning.
### Detailed Analysis or Content Details
The diagram shows a cyclical process:
1. The **App** sends **context** to the **Client**.
2. The **Client** returns a **decision** to the **App**.
3. The **App** generates a **reward** based on the decision and sends it back to the **Client**.
4. The **Client** sends the **best model** to the **Online Learning** module.
5. The **Join Server** receives **Interactions & Rewards**.
6. The **Join Server** sends **Training Data** to the **Data** storage.
7. The **Online Learning** module outputs **Parameters/Models** to the **Offline Learning** module.
8. The **Offline Learning** module receives data from the **Data** storage.
The diagram does not contain numerical data or specific values. It is a conceptual representation of a system architecture.
### Key Observations
The diagram highlights the interplay between online and offline learning. Online learning operates in real-time, while offline learning leverages stored data for more comprehensive model updates. The "Join Server" acts as a central hub for collecting interaction data. The flow of information is largely unidirectional, with feedback loops for continuous improvement.
### Interpretation
This diagram represents a common architecture for reinforcement learning systems. The separation of online and offline learning allows for both rapid adaptation to changing environments (online) and more robust model building using historical data (offline). The client-server model enables scalability and flexibility, allowing the application to interact with the learning modules through a standardized interface. The iterative process of context-decision-reward is fundamental to reinforcement learning, where the agent learns to maximize cumulative rewards through trial and error. The diagram suggests a system designed for continuous learning and improvement, where the model is constantly refined based on new interactions and data.