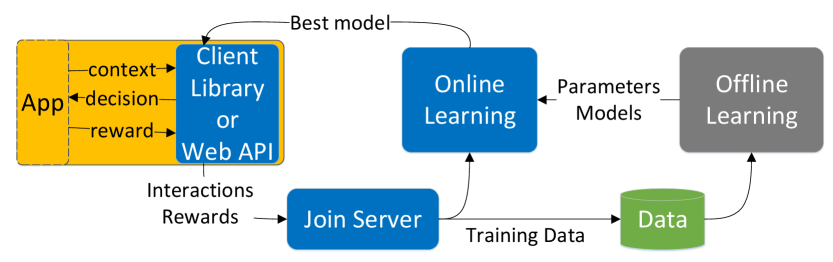
## Flowchart: System Architecture for Reinforcement Learning with Online/Offline Learning
### Overview
The flowchart depicts a reinforcement learning system where an application (App) interacts with a client library or web API, which connects to online learning. The best model from online learning is fed back to the app. Offline learning processes data from the server to generate parameters/models, which are then used in online learning. The app sends interactions and rewards to a server via a "Join Server" component, which contributes to training data.
### Components/Axes
- **Blocks**:
- **App** (Yellow): Contains "context," "decision," and "reward."
- **Client Library or Web API** (Blue): Connects the app to online learning.
- **Online Learning** (Blue): Outputs "Best model" and sends "Parameters Models" to offline learning.
- **Offline Learning** (Gray): Processes "Data" to generate "Parameters Models."
- **Join Server** (Blue): Aggregates "Interactions Rewards" from the app.
- **Data** (Green): Stores training data for offline learning.
- **Arrows**:
- Flow from App → Client Library/Web API → Online Learning.
- Feedback from Online Learning → App (Best model).
- Parameters Models flow from Online Learning → Offline Learning → Online Learning.
- Interactions Rewards flow from App → Join Server → Data.
### Detailed Analysis
1. **App**:
- Sends "context," "decision," and "reward" to the client library/web API.
- Receives "Best model" from online learning.
2. **Client Library/Web API**:
- Acts as an intermediary between the app and online learning.
3. **Online Learning**:
- Receives data from the client library/web API.
- Outputs "Best model" to the app.
- Sends "Parameters Models" to offline learning.
4. **Offline Learning**:
- Uses "Data" (from the server) to generate "Parameters Models."
- Feeds these models back into online learning.
5. **Join Server**:
- Collects "Interactions Rewards" from the app.
- Contributes to the "Data" pool for offline learning.
6. **Data**:
- Stores aggregated training data from the server.
### Key Observations
- **Feedback Loops**:
- Online learning continuously improves via feedback from the app ("Best model").
- Offline learning refines models using historical data, which are then used online.
- **Data Flow**:
- Real-time interactions (app → server) and batch processing (offline learning) are integrated.
- **Separation of Concerns**:
- Online learning handles immediate model updates, while offline learning focuses on large-scale data processing.
### Interpretation
This architecture suggests a hybrid reinforcement learning system where:
- **Real-Time Adaptation**: The app’s decisions are optimized using the "Best model" from online learning, which updates dynamically based on user interactions.
- **Scalability**: Offline learning processes large datasets to refine models, reducing the computational load on online learning.
- **Reinforcement Mechanism**: Rewards from the app’s interactions drive model improvements, creating a closed-loop system for continuous learning.
- **Potential Trade-offs**:
- Online learning may prioritize speed, while offline learning ensures robustness through extensive data analysis.
- The separation could introduce latency if synchronization between online/offline models is not seamless.
The system emphasizes iterative improvement, balancing immediate responsiveness with long-term optimization.