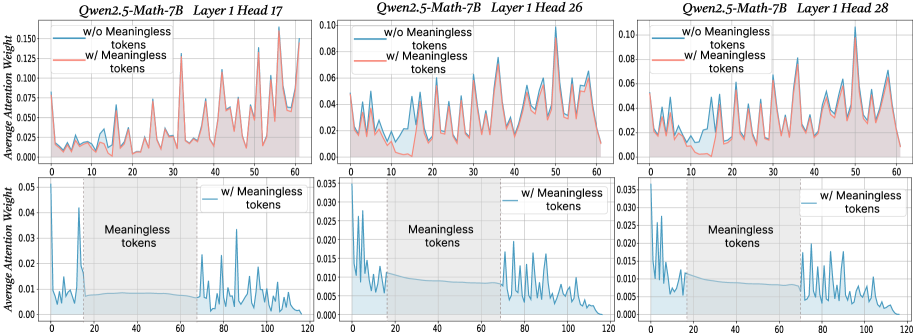
\n
## Line Charts: Attention Weight Analysis with and without Meaningless Tokens
### Overview
The image presents six line charts, arranged in two rows and three columns. Each chart compares the attention weight distribution with and without "meaningless tokens" for different layers of the Qwen2.5-Math-7B model. The top row displays attention weight, while the bottom row displays average attention weight. Each chart is labeled with the model name, layer number, and head number.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Token position, ranging from 0 to approximately 60-120 (depending on the chart).
* **Y-axis (Top Row):** Attention Weight, ranging from 0 to approximately 0.15.
* **Y-axis (Bottom Row):** Average Attention Weight, ranging from 0 to approximately 0.04.
* **Lines:** Two lines are present in each top-row chart:
* Red line: "w/o Meaningless tokens"
* Blue line: "w/ Meaningless tokens"
* **Lines (Bottom Row):** One line is present in each bottom-row chart:
* Teal line: "Meaningless tokens"
* **Titles:** Each chart has a title indicating the model, layer, and head. For example, "Qwen2.5-Math-7B Layer 1 Head 17".
### Detailed Analysis or Content Details
**Chart 1: Qwen2.5-Math-7B Layer 1 Head 17**
* **Top Row:** The red line (w/o Meaningless tokens) fluctuates between approximately 0.01 and 0.13, with several peaks. The blue line (w/ Meaningless tokens) fluctuates between approximately 0.005 and 0.08, with generally lower peaks.
* **Bottom Row:** The teal line (Meaningless tokens) starts at approximately 0.015 and rises to a peak of around 0.035 at token position 20, then declines to approximately 0.01 by token position 120.
**Chart 2: Qwen2.5-Math-7B Layer 1 Head 26**
* **Top Row:** The red line (w/o Meaningless tokens) fluctuates between approximately 0.01 and 0.07. The blue line (w/ Meaningless tokens) fluctuates between approximately 0.005 and 0.05, with generally lower peaks.
* **Bottom Row:** The teal line (Meaningless tokens) starts at approximately 0.01 and rises to a peak of around 0.025 at token position 20, then declines to approximately 0.01 by token position 120.
**Chart 3: Qwen2.5-Math-7B Layer 1 Head 28**
* **Top Row:** The red line (w/o Meaningless tokens) fluctuates between approximately 0.01 and 0.06. The blue line (w/ Meaningless tokens) fluctuates between approximately 0.005 and 0.04, with generally lower peaks.
* **Bottom Row:** The teal line (Meaningless tokens) starts at approximately 0.01 and rises to a peak of around 0.03 at token position 20, then declines to approximately 0.015 by token position 120.
**Trends:**
* In all charts, the red line (w/o Meaningless tokens) generally exhibits higher attention weights than the blue line (w/ Meaningless tokens).
* The teal lines (Meaningless tokens) in the bottom row all show a similar pattern: an initial rise followed by a decline.
### Key Observations
* The inclusion of meaningless tokens consistently reduces the overall attention weight, as evidenced by the lower values of the blue lines compared to the red lines in the top-row charts.
* The meaningless tokens themselves receive some attention, as shown by the teal lines in the bottom-row charts, but this attention diminishes over the sequence of tokens.
* The attention weight distributions appear to be somewhat noisy, with frequent fluctuations.
### Interpretation
The data suggests that the Qwen2.5-Math-7B model allocates less attention to relevant tokens when meaningless tokens are present. This is expected, as the model's attention mechanism is likely distributed across all tokens in the input sequence. The decreasing attention to meaningless tokens over the sequence could indicate that the model learns to ignore them as it processes the input.
The differences in attention weight distributions between the layers and heads suggest that different parts of the model may be affected differently by the presence of meaningless tokens. The noisy attention weight distributions could be due to the inherent stochasticity of the attention mechanism or the complexity of the input data.
The charts provide insights into how the model handles irrelevant information and how this affects its attention allocation. This information could be useful for improving the model's robustness and efficiency. The consistent pattern across the three charts suggests a generalizable effect of meaningless tokens on attention weights within this model architecture.