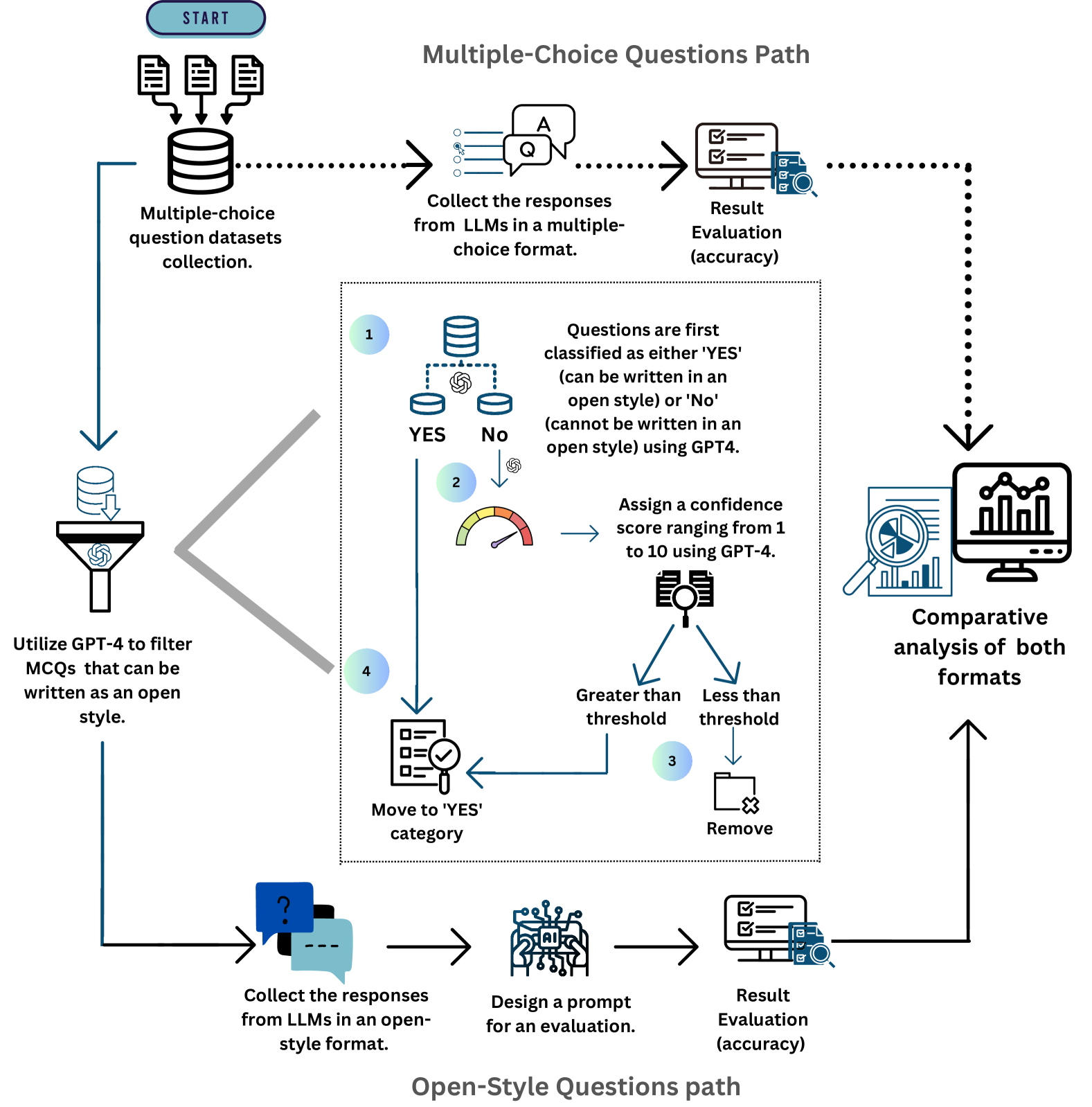
## Flowchart: Evaluation Process for LLM Question Formats
### Overview
The flowchart illustrates a two-path evaluation system for assessing multiple-choice (MCQ) and open-style questions generated by Large Language Models (LLMs). It includes data collection, classification, accuracy evaluation, and comparative analysis. Key components involve GPT-4 for filtering and scoring, confidence thresholds, and visual comparison of formats.
### Components/Axes
1. **Paths**:
- **Multiple-Choice Questions Path** (left): Starts with dataset collection, response gathering, and accuracy evaluation.
- **Open-Style Questions Path** (bottom): Involves open-format response collection, prompt design, and evaluation.
2. **Decision Nodes**:
- Classification of questions as "YES" (can be written in open style) or "NO" (cannot be written in open style) using GPT-4.
- Confidence score assignment (1–10) for "YES" questions via GPT-4.
3. **Evaluation Metrics**:
- Accuracy evaluation for both paths.
- Comparative analysis using a bar chart (right side).
### Detailed Analysis
1. **Data Flow**:
- **MCQ Path**:
- Collect MCQ datasets → Gather LLM responses in MCQ format → Evaluate accuracy.
- Classify questions as "YES" or "NO" using GPT-4.
- Assign confidence scores (1–10) to "YES" questions.
- If score > threshold → Move to "YES" category; else → Remove.
- **Open-Style Path**:
- Collect LLM responses in open-style format → Design evaluation prompt → Evaluate accuracy.
2. **Visual Elements**:
- **Gauge**: Confidence score range (1–10) with a needle indicator.
- **Bar Chart**: Comparative analysis of both formats (no numerical values provided).
3. **Thresholds**:
- Unspecified confidence score threshold for categorization.
### Key Observations
- **Bifurcation**: The process splits into two distinct paths for MCQ and open-style questions.
- **GPT-4 Dependency**: Critical for classification and confidence scoring, introducing automation but potential bias.
- **Threshold Ambiguity**: The confidence score threshold is not quantified, leaving implementation details undefined.
- **Comparative Analysis**: Visualized via a bar chart, but specific data points are missing.
### Interpretation
The flowchart emphasizes a structured approach to optimizing LLM-generated questions by separating formats and evaluating their suitability for open-style conversion. The use of GPT-4 for classification and scoring suggests an attempt to standardize evaluation, though the lack of threshold specificity and missing bar chart data limits transparency. The comparative analysis implies a focus on identifying which formats perform better under specific criteria, potentially guiding LLM training or prompt engineering. The absence of numerical results in the bar chart raises questions about the practical utility of the comparison without concrete metrics.